高度計算機はHPCテックにお任せください。






Information
- トップページ
- Information
- [NVIDIA] 次世代のアクセラレーテッドコンピューティング、 Hopperアーキテクチャを発表
2022/04/12
[NVIDIA] 次世代のアクセラレーテッドコンピューティング、 Hopperアーキテクチャを発表

NVIDIA社は、新たな GPUアーキテクチャ NVIDIA Hopperと Hopperベースの GPU、NVIDIA H100を発表しました。H100は、最先端の TSMC 4Nプロセスを使用し 800億のトランジスタで構築された世界で最も先進的なチップです。PCIe Gen5や HBM3を利用した最初の GPUでもあり 3TB/sのメモリ帯域を実現し、大規模な AIと HPCを加速します。
画期的なイノベーションと強化ポイント
・Transformerネットワークを前世代よりも 6倍高速化する新しい Transformer Engine
・第 2世代の Secure Multi Instance GPU
・処理中に AIモデルと顧客データを保護するコンフィデンシャルコンピューティング
・第 4世代 NVIDIA NVLink
・新しい DPX命令
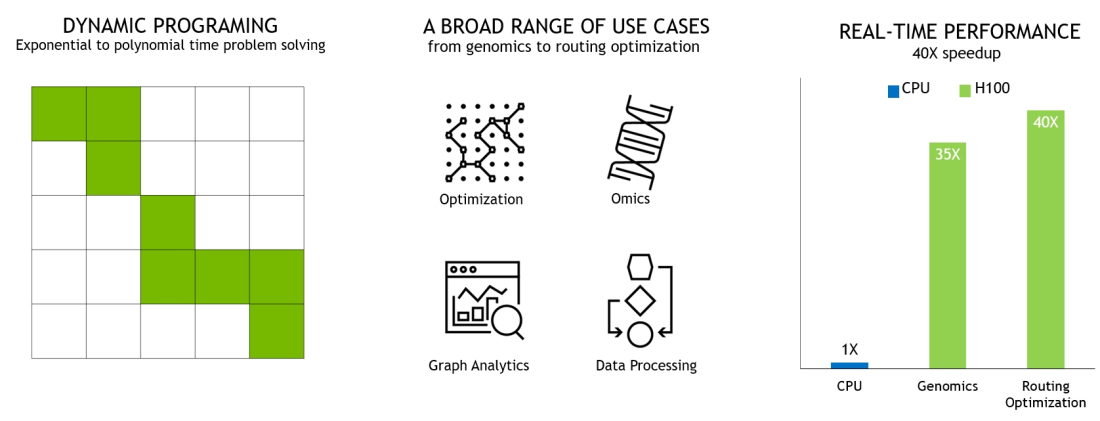
DPX Instructions Accelerate Dynamic Programming
H100は、第 4世代の Tensorコア と新たに搭載された Transformer Engineと FP8の採用によって、Mixture of Experts(MoE)の学習は前世代よりも最大 9倍に、5,300億パラメータからなる Megatron Chatbotの推論は遅延を最小に抑えながら最大 30倍に加速されます。
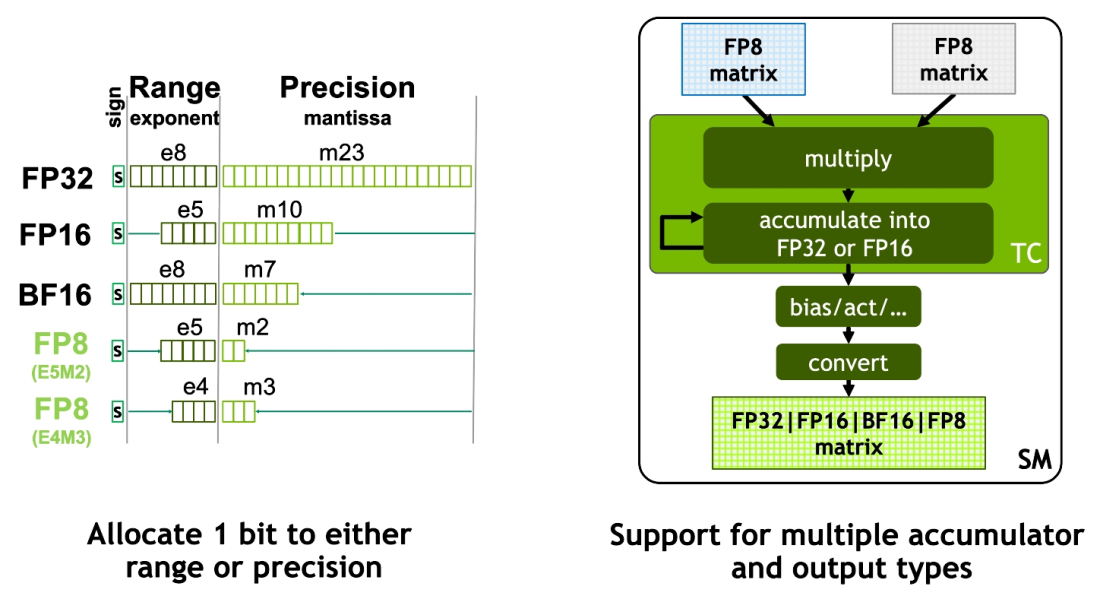
New Hopper FP8 Precisions – 2x throughput and half the footprint of H100 FP16 / BF16
・演算ユニット SMが増加
・L1キャッシュが 256KB、L2キャッシュ が 50MB増加
・第 4世代 Tensorコア は FP8を新しくサポート
・FP32や FP64の FMAが 2倍高速に
・Thread Block Cluster導入(新しい CUDA仕組み)
・TMA(Tensor Memory Accelerator)の導入(非同期データ転送の仕組み)
・第 4世代の NVSwitchに対応(NVLinkだけで最大 256のGPUを接続可)
・世界初の HBM3 GPUメモリアーキテクチャ、帯域幅は前世代の 2倍
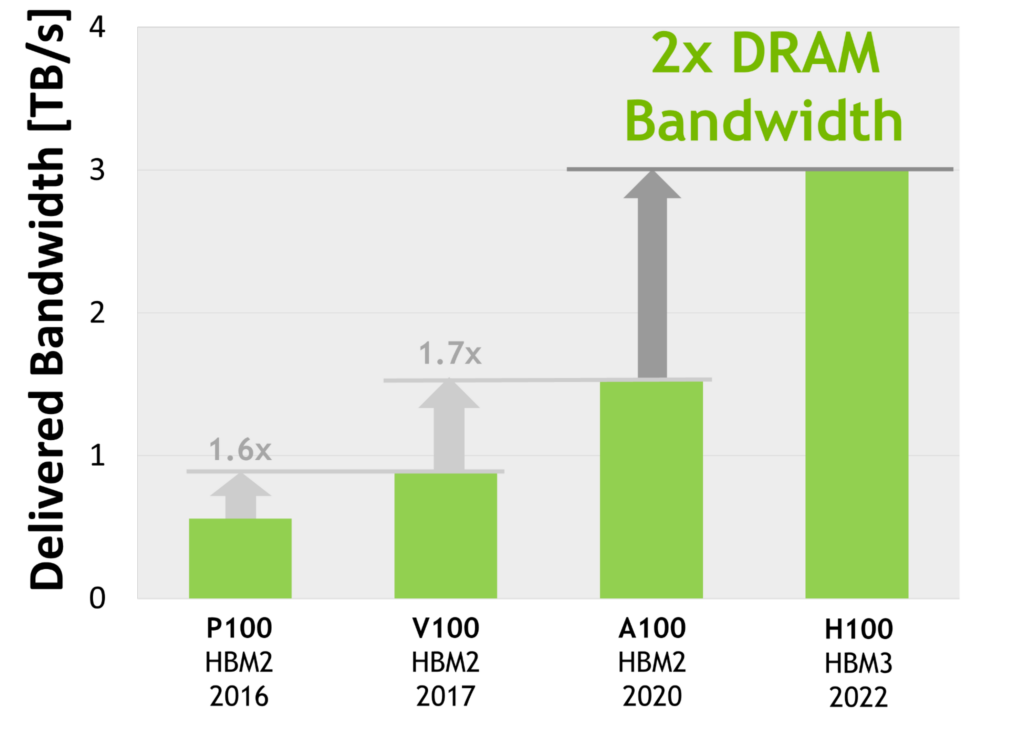
World’s First HBM3 GPU Memory Architecture, 2x Delivered Bandwidth
NVIDIA H100 GPU Features
| NVIDIA A100 | NVIDIA H100 SXM51 |
NVIDIA H100 PCIe1 |
||
| GPU Architecture | NVIDIA Ampere | NVIDIA Hopper | NVIDIA Hopper | |
| GPU Board Form Factor | SXM4 | SXM5 | PCIe Gen 5 | |
| SMs | 108 | 132 | 114 | |
| TPCs | 54 | 66 | 57 | |
| FP32 Cores / SM | 64 | 128 | 128 | |
| FP32 Cores / GPU | 6912 | 16896 | 14592 | |
| FP64 Cores / SM (excl. Tensor) |
32 | 64 | 64 | |
| FP64 Cores / GPU (excl. Tensor) |
3456 | 8448 | 7296 | |
| INT32 Cores / SM | 64 | 64 | 64 | |
| INT32 Cores / GPU | 6912 | 8448 | 7296 | |
| Tensor Cores / SM | 4 | 4 | 4 | |
| Tensor Cores / GPU | 432 | 528 | 456 | |
| GPU Boost Clock (Not finalized for H100)3 |
1410 MHz | Not finalized | Not finalized | |
| Peak FP8 Tensor TFLOPS with FP16 Accumulate1 |
N/A | 2000/40002 | 1600/32002 | |
| Peak FP8 Tensor TFLOPS with FP32 Accumulate1 |
N/A | 2000/40002 | 1600/32002 | |
| Peak FP16 Tensor TFLOPS with FP16 Accumulate1 |
312/6242 | 1000/20002 | 800/16002 | |
| Peak FP16 Tensor TFLOPS with FP32 Accumulate1 |
312/6242 | 1000/20002 | 800/16002 | |
| Peak BF16 Tensor TFLOPS with FP32 Accumulate1 |
312/6242 | 1000/20002 | 800/16002 | |
| Peak TF32 Tensor TFLOPS1 | 156/3122 | 500/10002 | 400/8002 | |
| Peak FP64 Tensor TFLOPS1 | 19.5 | 60 | 48 | |
| Peak INT8 Tensor TOPS1 | 624/12482 | 2000/40002 | 1600/32002 | |
| Peak FP16 TFLOPS (non-Tensor)1 |
78 | 120 | 96 | |
| Peak BF16 TFLOPS (non-Tensor)1 |
39 | 120 | 96 | |
| Peak FP32 TFLOPS (non-Tensor)1 |
19.5 | 60 | 48 | |
| Peak FP64 TFLOPS (non-Tensor)1 |
9.7 | 30 | 24 | |
| Peak INT32 TOPS1 | 19.5 | 30 | 24 | |
| Texture Units | 432 | 528 | 456 | |
| Memory Interface | 5120-bit HBM2 | 5120-bit HBM3 | 5120-bit HBM2e | |
| Memory Size | 40 GB | 80 GB | 80 GB | |
| Memory Data Rate (Not finalized for H100)1 |
1215 MHz DDR | Not finalized | Not finalized | |
| Memory Bandwidth1 | 1555 GB/sec | 3000 GB/sec | 2000 GB/sec | |
| L2 Cache Size | 40 MB | 50 MB | 50 MB | |
| Shared Memory Size / SM | Configurable up to 164 KB |
Configurable up to 228 KB |
Configurable up to 228 KB |
|
| Register File Size / SM | 256 KB | 256 KB | 256 KB | |
| Register File Size / GPU | 27648 KB | 33792 KB | 29184 KB | |
| TDP1 | 400 Watts | 700 Watts | 350 Watts | |
| Transistors | 54.2 billion | 80 billion | 80 billion | |
| GPU Die Size | 826 mm2 | 814 mm2 | 814 mm2 | |
| TSMC Manufacturing Process |
7 nm N7 | 4N customized for NVIDIA |
4N customized for NVIDIA |
|
1.Preliminary specifications for H100 based on current expectations and are subject to
change in the shipping products
2.Effective TOPS / TFLOPS using the Sparsity feature
3.GPU Peak Clock and GPU Boost Clock are synonymous for NVIDIA Data Center GPUs
NVIDIA H100 Tensor Core GPU Architecture V1.02

NVIDIA DGX H100 – 日本語版
