高度計算機はHPCテックにお任せください。






Information
- トップページ
- Information
- [TECH Report] JOB 管理システム “Slurm” のご紹介
2020/06/02
[TECH Report] JOB 管理システム “Slurm” のご紹介
TECH Report は HPC テックスタッフからの情報発信です。

弊社では JOB 管理システムとして、Altair Grid Engine、pbspro-ce※、IBM Spectrum LSF-C※、SGE、Torque、そして Slurm などのインストールサービスを、弊社ワークステーションやサーバをお買い上げのお客様のご依頼によりご提供しています。
今回は、これら JOB 管理システムの違いや選び方、そして弊社が推奨する Slurm について簡単にご紹介します。
※:無償のコミュニティエディション
JOB 管理はどんなことができるの?
クラスタシステムをマルチユーザ環境で利用する場合や、多くのデータケース計算を全体として効率的に早く完了させたい、また、他からの影響を極力除外して早く計算を完了させることを望む場合は、JOB 管理システムを導入するのが手っ取り早い解決策です。
様々な製品がありますが、基本的には、システムが自動的に空いている CPU や GPU、メモリー等のリソース、プライオリティ、予想/指定実行時間を考慮して(backfill)スケジューリングすることが可能です(slurm への設定パラメータに依存します)。
ここで言う「JOB」とは、プログラムの実行コマンドとその条件を指定された書式で記したものを示します。
例えば slurm の場合、下記のような内容を記し、ファイルに保存します。
ファイル:batchの内容
#!/bin/bash #SBATCH -n 2 #SBATCH –tasks-per-node=1 mpirun ./a.out
1行目は bash スクリプト定義です。2行目には slurm への指示が書かれています。ここではプロセス数(コア数)2個を予約しています。3行目にノード当たりのプロセス数を指定します。最終行でプログラム a.out を実行します。こうするとノード当たり 1個 MPIプロセスが起動して合計2ノード、2プロセスで MPI 実行することができます。
これを実行するには、slurm システムでは sbatch というコマンドを使って、JOB をシステムへ投入します。
$ sbatch batch
これで slurm サービスがファイル batch で指定されたコア数を予約し、システム内のいずれかの 2ノードで各 1コアが空いていれば、実行を開始し、終了したら結果をファイルに書き出して JOB を終了します。上記のように出力ファイルの指定がない場合は、デフォルトでファイル:slurm-<JOB-ID>.out に 出力結果が保存されます。
上記のように、JOB 管理システムでは一般に、コア数の他、メモリサイズ、GPU 数、ノード数、計算時間等の計算ノードのリソースを予約するオプション、あるいはそれらリソース制限を管理する機能が備わっています。
どれを使えばいいの?
少人数の研究室などで利用するには、一部のパッケージを除いてどの JOB 管理システムも機能的に大きな違いは有りません。JOB 管理システムの選択には、これまで使っていた経験がある場合は、使い勝手の似たものを選択すればよいです。ただし、GPU スケジューリングに関しては、より新しい、開発が維持されているものを採用するのが無難です(GPU の進歩が早いため)。
弊社の取扱製品では、Unuva Grid Engine が最も高機能です。無償の SGE を大幅に高機能化したもので、国内の大型計算機センターにおいても採用されています。pbspro-ce は PBSpro のコミュニティエディションとして無償で利用できます。古くからある pbs 系のコマンド体系に慣れていらっしゃるお客様が選択されています。pbs 系には他に無償の Torque もありますが、これ単体ではpbspro-ce に比べて機能面で劣る面があります。まだまだユーザ数は割と多いと思われますが、最後の更新が 2018年と古いものです。この他、IBM 社の LSF 製品にはコミュニティバージョンがあります。
これら GridEngine 系、PBS 系、LSF 系、および弊社推奨の無償の Slurm について、各々のシステムを利用する際に用いる各種コマンドの対比表が Slurm ドキュメンテーションの Web ページに掲載されていますのでご参考にしてください。
https://slurm.schedmd.com/rosetta.html
GPU スケジューリングをご希望の場合は、できる限り開発が新しい JOB 管理システムをお勧めします。無償版では slurm あるいは pbspro-ce が有望な選択肢です。
上記に掲載がない JOB 管理システムのインストール代行についてはご相談ください。
Slurmとは
フリーソフトでの弊社の推奨は Sched_MD 社の slurm です。これは他のパッケージと比較して新しく開発されているものですが、バグ修正が早く安定性や管理のしやすさに優れ、近年欧米のスーパーコンピュータセンターに多く採用されています。GPU スケジューリングも可能です。ベンチマーク TOP500 の上位 10システムの半分以上が slurm を利用しています。Slurm は下記に記す特徴を持ちます。
・クラスタ構成でも最小で一構成ファイル slurm.conf(GPU は gres.conf)で管理可能
・インストール、構成変更、ノード拡張が容易
・GPU / docker / Singularity との親和性
Slurm はミニマル構成で、サーバサービスとして「コントロールサービス」slurmctld デーモンと、クライアントサービスとして「コンピュートノードサービス」slurmd デーモンの両サービスと、ノードやパーティション(キュー)構成を定義する slurm.conf ファイルがあれば動作します。通常は、slurmctld は管理ノード、slurmd は計算ノードに配置し、slurm.conf ファイルは NFS 共有します。GPU スケジューリングをしたい場合は、gres.conf と呼ばれる構成ファイルも追加で設定します。
弊社の標準構成では、コア数をリソースとして定義してノード上で複数 JOB 実行を許可しています。また、プロセス追跡には cgroup を用います。ログは / var / log 配下に出力されます。
構成ファイルはテキスト編集、slurm デーモンサービスは systemctl コマンドで操作というシンプルな管理が可能です。計算ノードを追加する際は、slurmd インストールと構成ファイルの設定のみで可能です。
弊社ではこのシンプルな構成を標準としてご提供してます。
ユーザが不特定多数で比較的規模の大きいシステムの場合は、JOB の履歴を蓄積表示するアカウンティング機能のご要望があるケースがあります。この機能は JOB 情報の蓄積に MariDB を使い、追加で slurmdbd サービスのインストールが必要となります。この機能についてはご依頼に応じてインストール設定しています。
また、現在実行されている JOB 一覧やパーティション(キュー)やノードリソースを GUI で表示する機能も備わっています。
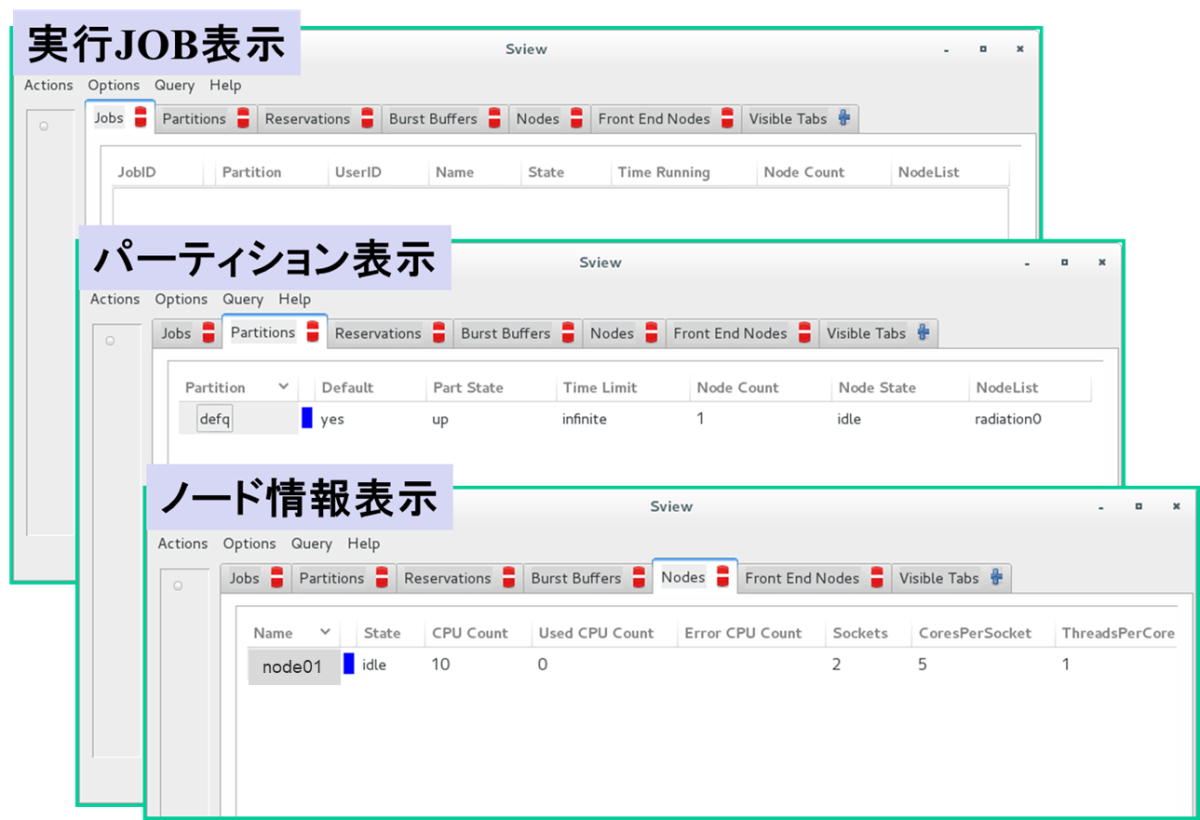
Slurmは 豊富なドキュメントが(英文ですが)Web で公開されていますので、ご興味のある方は下記 Web ページを参照ください。
HPC TECH Engineer : Murase