高度計算機はHPCテックにお任せください。






HPCTECH Solution
- トップページ
- 製品案内:ハードウェア
- AMD XILINX VCK5000
AMD XILINX VCK5000 Versal AI推論開発カード

AMD XILINX VCK5000 Versal 開発カードは業界標準 AI ベンチマークで世界初のゼロダークシリコン(ワットあたりの計算効率がほぼ 100%)を達成し、NVIDIA 社の主力 GPU と比較して 2倍の費用対効果を提供する VCK5000 は、ラックマウントサーバやワークステーションでの CNN、RNN、NLP アクセラレーションに最適な開発プラットフォームです。

AMD XILINX VCK5000 仕様
| カードの仕様 | VCK5000 | ||
| デバイス | VC1902 | ||
| コンピューティング | アクティブ | パッシブ | |
| INT8 TOPS (ピーク) | 145 | 145 | |
| サイズ | 高さ | フル | フル |
| 長さ | フル | 3/4 | |
| 幅 | デュアル スロット | デュアル スロット | |
| メモリ | DDR メモリ容量 | 16 GB | 16 GB |
| DDR 総帯域幅 | 102.4 GB/s | 102.4 GB/s | |
| 内部 SRAM の容量 | 23.9 MB | 23.9 MB | |
| 内部 SRAM の総帯域幅 | 23.5 TB/s | 23.5 TB/s | |
| インターフェイス | PCI Express | 43MB | 57MB |
| ネットワーク インターフェイス | 37TB/s | 47TB/s | |
| ロジック リソース | ルックアップ テーブル (LUT) | 899,840 | 899,840 |
| 消費電力と熱 | 最大総消費電力 | 225W | 225W |
| 熱冷却 | アクティブ | パッシブ | |
※アクティブファンは取り外し式です。

AI 推論
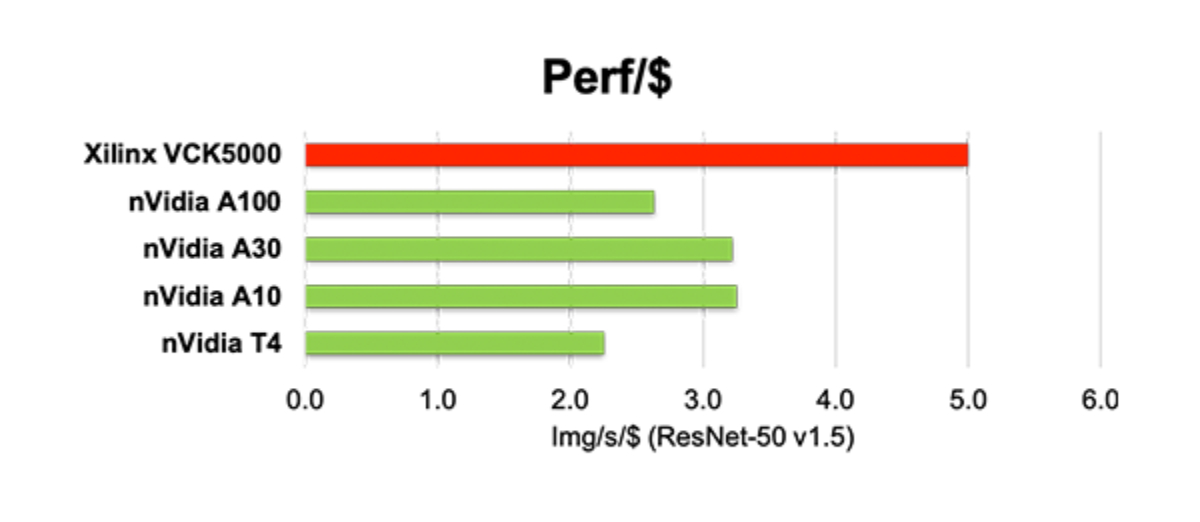
2倍の TCO削減(主流の GPUと比較)
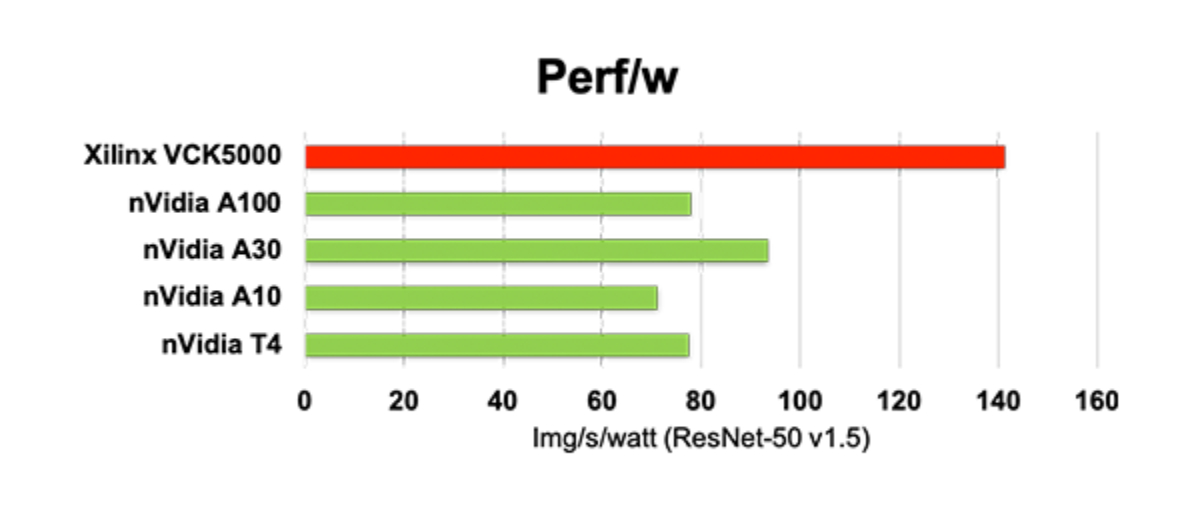
ワットあたり性能と価格性能比は 2倍(NVIDIA Ampereと比較)
90%の計算効率を達成
消費電力は 100W以下(カードレベル)
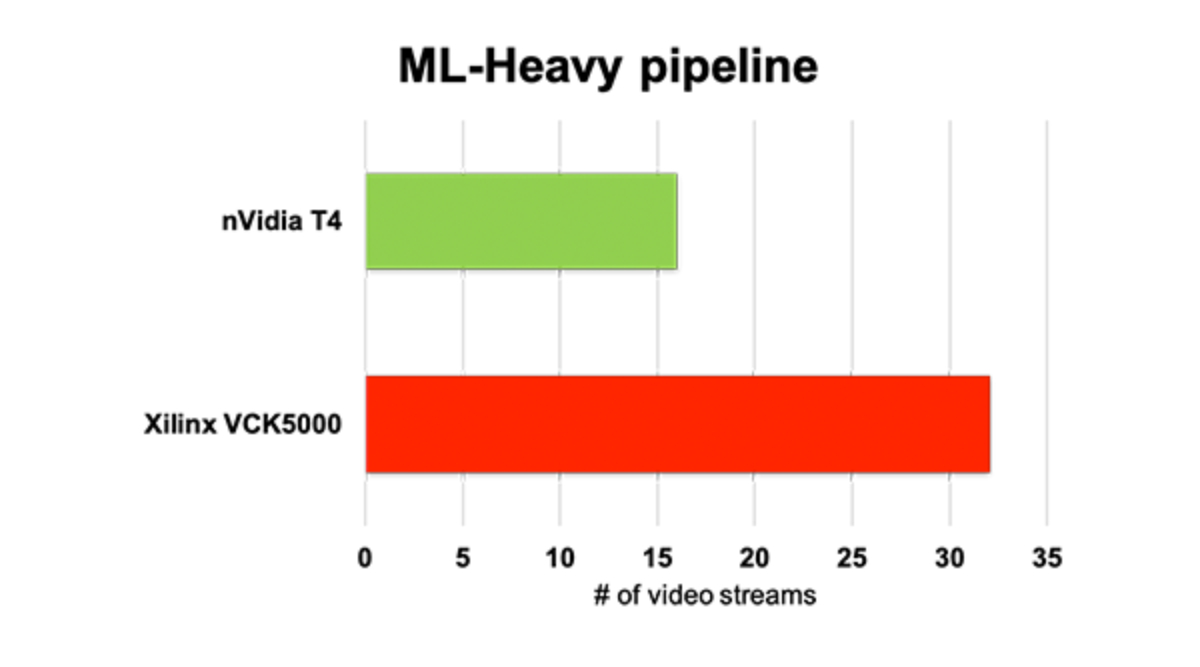
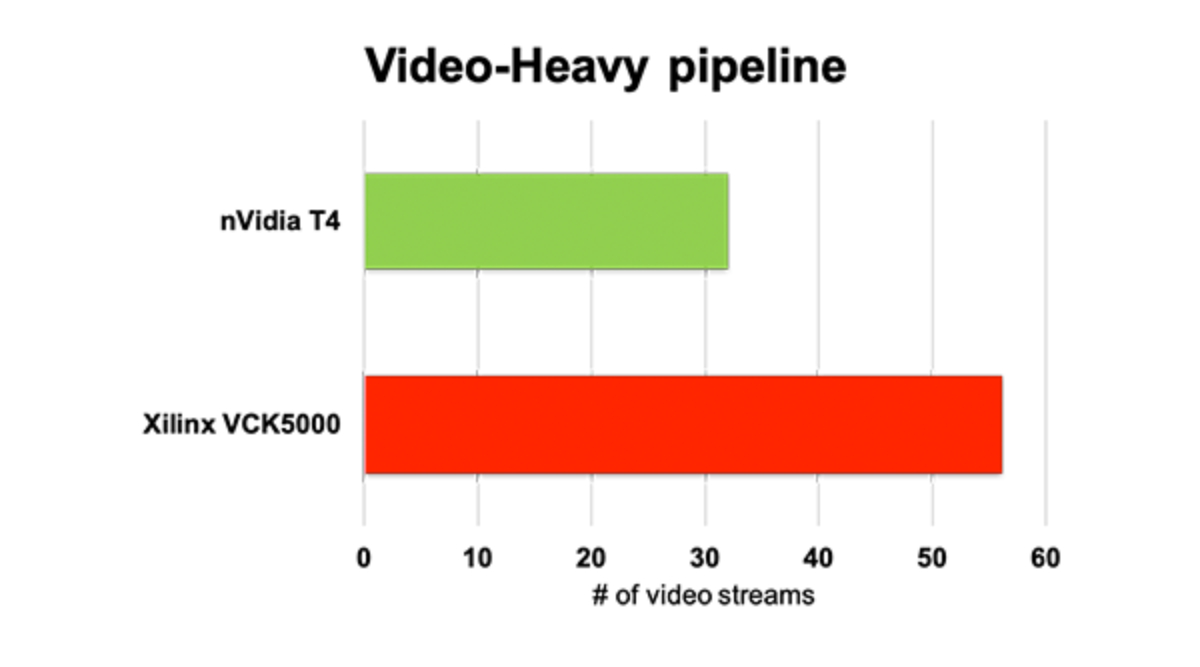
エンドツーエンドのビデオ解析スループットは NVIDIA GPUの 2倍
H.264デコードからコンピュータービジョンまで、最大 10個の AIモデルでフルパイプラインを実装
x86 CPUまたは単一の U30 Alveoカードでビデオデコードと CVを実行
FFmpeg / Gstreamerを使用するプラグインのパイプライン設計
ML Heavy: H.264 Decode + Yolov3 + 3x ResNet-18
Video Heavy: H.264 Decode + tinyYolov3 + 3x ResNet-50
使い慣れたフレームワークで作業が簡単
ハードウェアプログラミングが不要な CPU / GPUユーザー向けのソフトウェアフロー
TensorFlowフレームワークを使用してボードで直接推論を実行
主要フレームワーク(Pytorch、TensorFlow、TensorFlow 2、Caffe)でサポートされる最先端モデル

包括的なサポート
| AI 開発者の方 | 学習済みの TensorFlow/Pytorch モデルを、Vitis AI や Mipsology Zebra で使用して Versal 上で直接推論を実行。 | ||
| AI エンジンとプログラマブルロジックでアルゴリズムの高速化を希望される方 | C/C++ を使用する抽象度の高い AI エンジン API と Vitis アクセラレーションライブラリを提供。 | ||
| Vitis フロー | ・X86 またはエンベデッドプロセッサで実行。 ・XRT でアクセラレータとの実行時の相互作用を管理。 ハードウェアコンポーネントやカーネルは、C/C++ で開発することも、PL や AI エンジンに対して RTL を使用して開発することも可能。 |
AMD XILINX サポートページリンク
https://support.xilinx.com/s/global-search/VCK5000?language=en_US
AMD XILINX VCK5000 Product Brief

>
Accelerating Deep Learning Models on Xilinx 7nm Versal Card
弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。
