高度計算機はHPCテックにお任せください。






GPU Solution:NVIDIA TESLA SERIES
- トップページ
- 製品案内
- GPUラインナップ
- NVIDIA TESLA SERIES
- TESLA P100
世界最先端のデータセンター GPU

NVIDIA TESLA P100 は、前例のない最先端のデータセンターアクセラレータです。新たに開発された NVIDIA Pascal GPU アーキテクチャにより、汎用ノード数百台分を超える性能を持つ世界最速の計算ノードが誕生しました。少ない台数で高い性能をもたらす超高速ノードにより、データセンターではスループットを大幅に向上させる一方で、コストを削減できます。
TESLA P100 によりアプリケーションのパフォーマンスが大幅に向上
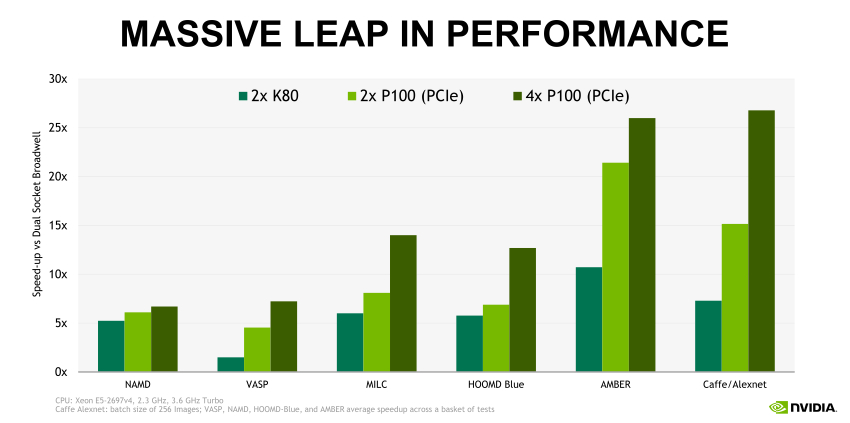
▲クリックすると拡大します。
▲クリックすると拡大します。
TESLA P100 アクセラレータの特徴と利点
TESLA P100 は半導体からソフトウェアまで新しい発想で構成され、随所に革新的な技術を使用しています。それぞれの先駆的テクノロジがパフォーマンスの劇的な飛躍をもたらし、世界最速の計算ノード開発を推進しています。
最新アーキテクチャにより業界最高の演算性能を実現
 |
新しい NVIDIA Pascal アーキテクチャの導入により、TESLA P100 は HPC やハイパースケールワークロードに対する最高水準の性能を獲得しました。21 テラフロップスを超える FP16 パフォーマンスを備えた Pascal は、ディープラーニングの刺激的な可能性を切り拓くのに最適なアーキテクチャです。 |
最新のメモリ技術を採用し高メモリ帯域を実現
| TESLA P100 は HBM2 テクノロジを実装した CoWoS (Chip on Wafer on Substrate) を組み込んで、コンピューティングとデータを同一パッケージに統合し、前世代の3倍を超えるメモリ性能を実現しています。 |  |
GPUインターコネクトによりスケーラビリティを最大化
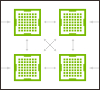 |
GPU 相互接続は往々にしてパフォーマンスを低下させます。革命的な NVIDIA NVLink 高速相互接続は、現存するクラス最高のテクノロジに比べて5倍のパフォーマンスを発揮し、複数の GPU にまたがるアプリケーションの展開を支えます。 注: PCIe 向けの TESLA P100 では利用できません。 |
簡潔なプログラミングを可能にするページマイグレーションエンジン
| ページマイグレーションエンジンのおかげで、開発者はデータの動きを管理することに気をとられず、コンピューティング性能のチューニングに集中できます。GPU の物理メモリサイズを超えて、最大 2 テラバイトまでアプリケーションを展開できるようになりました。 | 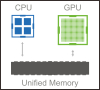 |
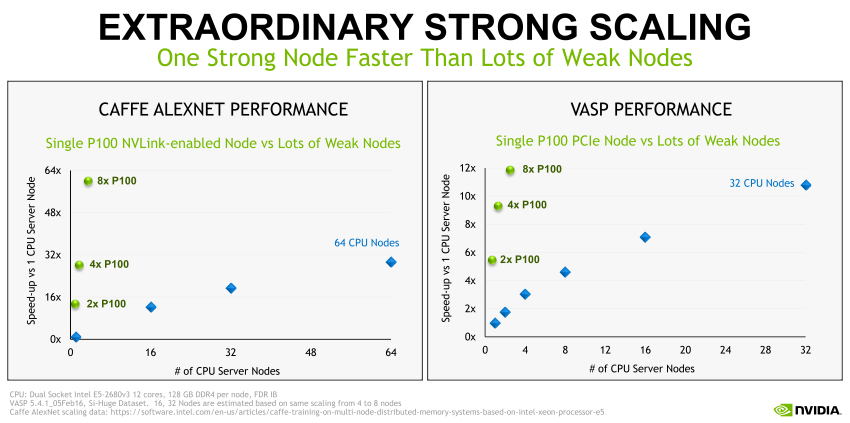
ストロングスケール HPC に対応する NVIDIA TESLA P100
TESLA P100 と NVIDIA NVLink テクノロジを搭載した超高速ノードでは、ストロングスケールアプリケーションの処理を加速し、より短時間で解決に導くことができます。NVLink により、1 台のサーバノードにつき最大 8 つの TESLA P100 を相互接続でき、帯域幅は PCIe の 5 倍になります。HPC やディープラーニングにおける膨大な計算を必要とする世界の最重要課題の解決を支援します。

混合ワークロード HPC に対応する NVIDIA TESLA P100
PCIe 向けの TESLA P100 を利用すると、混合ワークロード HPC データセンターでスループットを大幅に向上させる一方で、コストを削減できます。たとえば、PCIe で相互接続した 4 つの TESLA P100 が駆動する 1 台の GPU アクセラレーションノードで、さまざまなアプリケーションに利用できる 32 台の汎用 CPU ノードを置き換えることができます。はるかに少ない台数の強力なノードですべてのジョブを完了できるため、お客様はデータセンターのコスト全体を最大 70% 削減できます。

製品仕様
|
P100 for |
P100 for |
|
| Double-Precision Performance | 4.7 TFLOPS | 5.3 TFLOPS |
| Single-Precision Performance | 9.3 TFLOPS | 10.6 TFLOPS |
| Half-Precision Performance | 18.7 TFLOPS | 21.2 TFLOPS |
| NVIDIA NVLink Interconnect Bandwidth | - | 160 GB/s |
| PCIe x16 Interconnect Bandwidth | 32 GB/s | 32 GB/s |
|
CoWoS HBM2 Stacked Memory Capacity |
16 GB 12 GB |
16 GB |
| CoWoS HBM2 Stacked Memory Bandwidth | 720 GB/s 540 GB/s |
720 GB/s |
| Enhanced Programmability with Page Migration Engine | ||
| ECC Protection for Reliability | ||
| Server-Optimized for Data Center Deployment |

弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。

製品案内
- NVIDIA Tensor Core GPU
- NVIDIA H100 NEW
- A800 40GB Active NEW
- NVIDIA A10
- NVIDIA A30
- NVIDIA A100
- NVIDIA V100s
- NVIDIA T4
- NVIDIA V100
- NVIDIA Quadro SERIES
- RTX 4500 Ada NEW
- RTX 4000 Ada NEW
- L40S NEW
- RTX 5000 Ada NEW
- RTX 4000 SFF Ada NEW
- RTX 6000 Ada NEW
- NVIDIA L40
- NVIDIA RTX A5500
- NVIDIA RTX A4500
- NVIDIA A40
- NVIDIA RTX A6000
- NVIDIA RTX A5000
- NVIDIA RTX A4000
- Quadro RTX8000 Passive
- Quadro RTX8000
- Quadro RTX6000
- Quadro GV100
- Quadro GP100
- Quadro P6000
- NVIDIA TITAN SERIES
- NVIDIA TITAN RTX
- NVIDIA TITAN V
- NVIDIA TITAN Xp
- NVIDIA TITAN Xp-SW
- NVIDIA GeForce SERIES
- GeForce RTX3090
- GeForce RTX2080Ti
- GeForce GTX1080Ti
- GeForce GTX1080
- GPUワークステーション
- HPCT WRSE31-4GP
- HPCT WR17as-4GP
- HPCT WR13as-4GP
- HPCT W117gs
- HPCT W116gs
- HPCT W216gs
- HPCT WR16gs
- HPCT WRSX42-4GP NEW
- HPCT WRSX31-4GP
- HPCT WRSX32-4GP
- HPCT WR26gs-Silent
- HPCT WR26gs
- GPUラックマウントサーバ
- HPCT RS2E41-4GP NEW
- HPCT RG2E42-4GPNEW
- HPCT RG2E31-4GP
- HPCT R217gg-4GP
- HPCT RG2E32-8GP
- HPCT R227gg-8GP
- HPCT RS4E42-8GP NEW
- HPCT RS4E32-8GP
- HPCT R427as-8GP
- HPCT R116gs
- HPCT RS1X32-4GP
- HPCT R126gs
- HPCT R126gs-4GP
- HPCT RS2X41-2GP NEW
- HPCT RS2X42-4GP NEW
- HPCT RS2X32-6GP
- HPCT R226gs
- HPCT R426gs-8GP
- HPCT RS4X42-8GP NEW
- HPCT RS4X32-10GP
- HPCT R426gs-10GP
- GPUラックマウントサーバ
- for NVLink - NVIDIA DGX H100 NEW
- NVIDIA DGX A100
- HPCT RS2E32-4GN
- HPCT R227as-4GN
- HPCT RS4X42-4GN NEW
- HPCT RS2X32-4GN
- HPCT R126gs-4GN
- HPCT RS4E32-8GN
- HPCT R427as-8GN
- HPCT RS4X32-8GN
- HPCT R426gs-8GN
- HPCT RX26gs-16GN
- 販売終息製品
- サービス
- セットアップサービス
- DL クラスタ管理
- ベンチマーク情報
- NVIDIA GPU CLOUD
- GPUアプリケーション
- 化学・量子化学
- AMBER
- GROMACS
- NAMD
- 量子化学
- GAMESS-UK
- GAMESS-US
- 物質科学
- VASP
- 数値解析
- MATLABS
- Mathematica
- 数値流体力学
- Ansys Fluent
- 構造力学
- Abaqus
- Ansys Mechanical
- LS-DYNA
- MSC Nastran
- MSC Marc
- 電磁界
- CST Microwave
Studio(MWS) - JMAG
- タンパク質構造解析
- AlphaFold
- RELION
- GPUユーザレポート
- GPU TEST DRIVE CENTER
- GPUテストドライブとは
- HPCT-Trial
- 導入事例
- 会社情報
- サポート
- お取引・お問い合わせ