高度計算機はHPCテックにお任せください。






GPU Solution:NVIDIA GPU
- トップページ
- 製品案内
- GPUラインナップ
- NVIDIA GPU
- NVIDIA V100
NVIDIA V100 Tensor Core GPUs

NVIDIA® V100 Tensor Core GPUs は、前世代 Pascal アーキテクチャを採用した TESLA P100 を超えた世界最先端の GPU アクセラレータです。メモリは 従来の 16GB 搭載版と新たに 32GB 搭載版が追加されました。
最新の GPU アーキテクチャである Volta を採用した NVIDIA V100 は、単一の GPU で CPU 100 個分のパフォーマンスを実現し、データサイエンティスト、研究者、エンジニアがかつては不可能だった課題に取り組むことを可能にします。
Volta ディープラーニングにおける性能向上
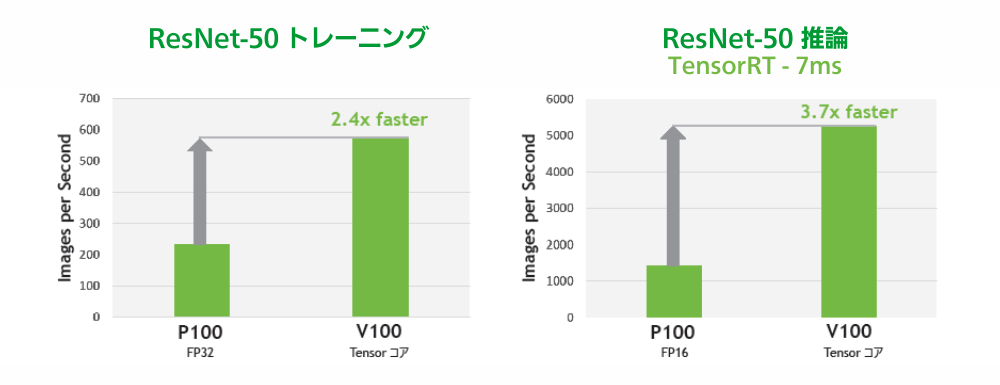
Pascal vs Volta GPU性能比較
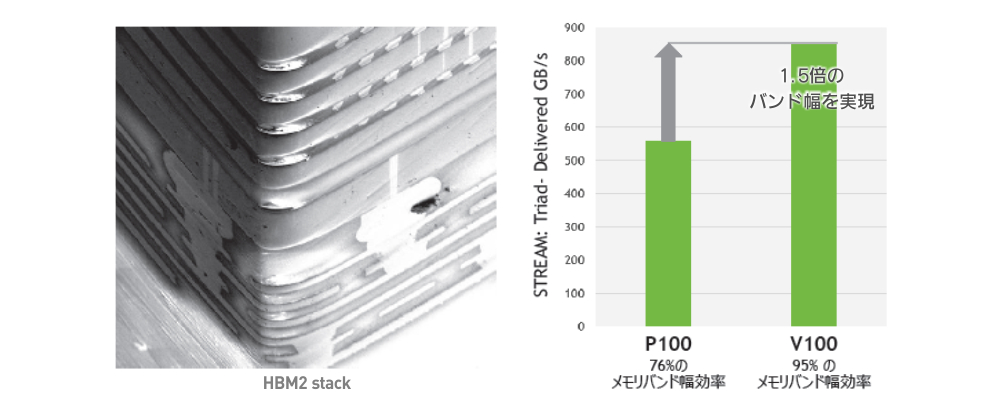
新しくなった HBM2 メモリ
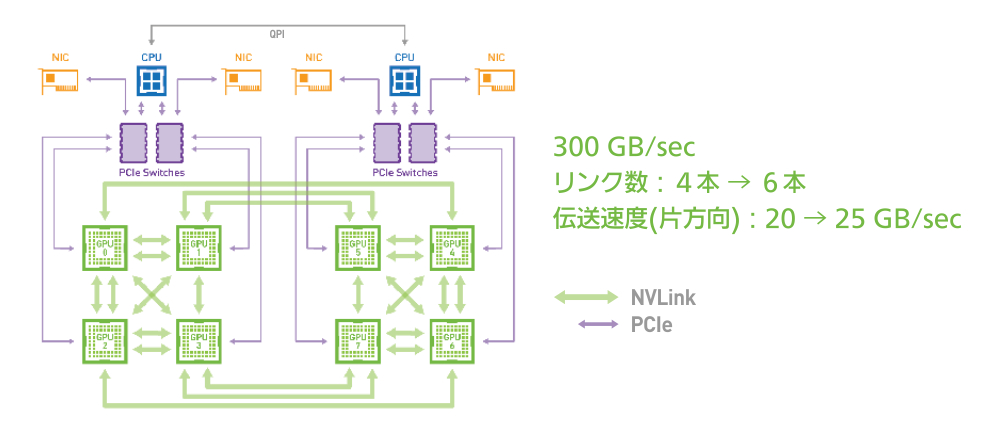
Volta NVLink
Volta GV100 SM

VOLTA TENSOR コア
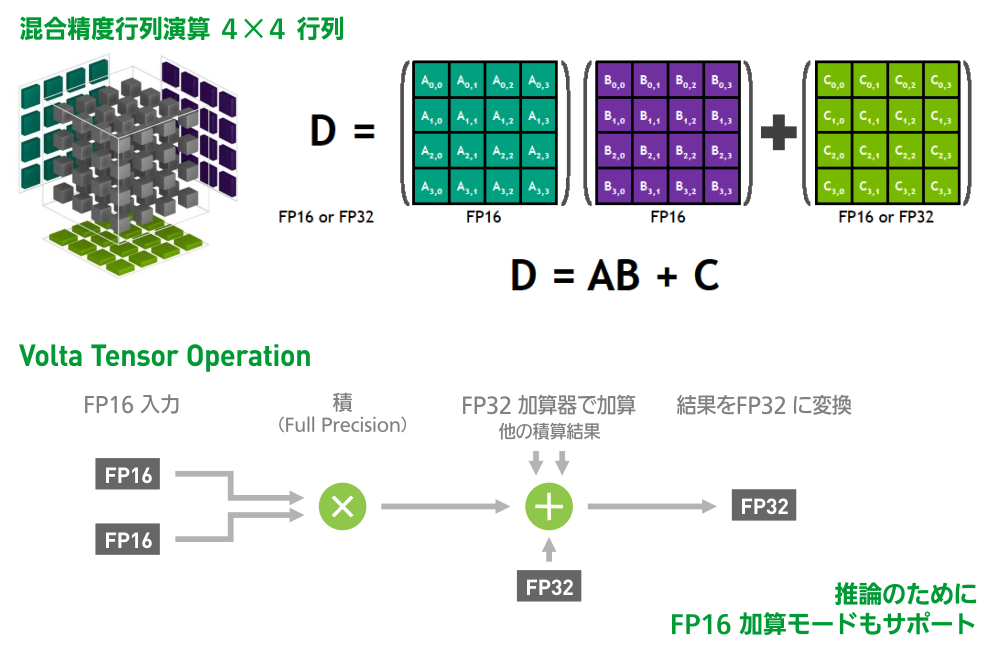
A GIANT LEAP FOR DEEP LEARNING
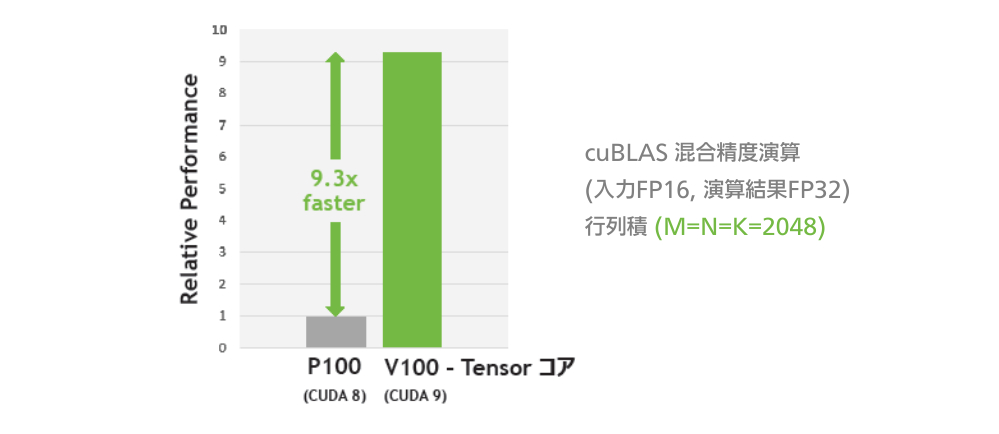
VOLTA MULTI-PROCESS SERVICE
NVIDIA V100の新機軸
NVIDIA V100 は半導体からソフトウェアまで新しい発想で構成され、随所に革新的な技術を使用しています。それぞれの先駆的テクノロジがパフォーマンスの劇的な飛躍をもたらします。
VOLTA アーキテクチャ
 |
CUDA コアと Tensor コアの組み合わせにより、NVIDIA V100 搭載サーバーの性能は HPC やディープラーニング用途で 100 台のコモディティ CPU サーバーに匹敵します。
|
TENSOR コア
|
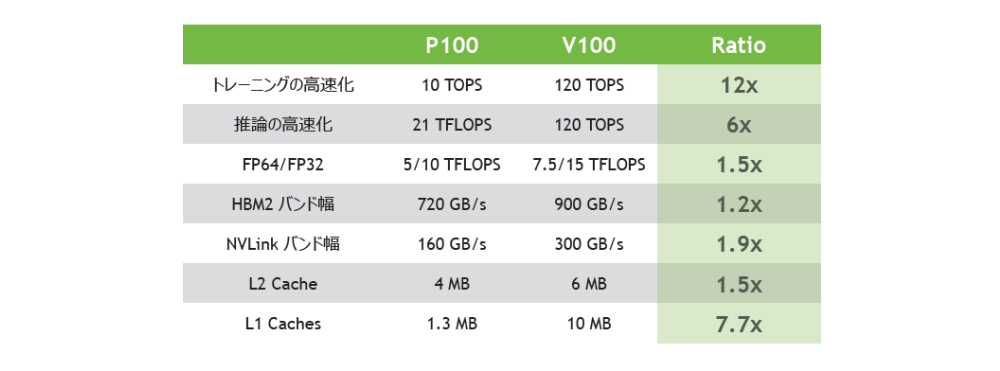
新たな 640 個の Tensor コアにより、TESLA V100 は 120 Tensor TeraFLOPS のディープラーニング性能を発揮。これは、NVIDIA Pascal 世代 GPU との比較で学習が 12 倍、推論は 6 倍のパフォーマンスです。 |
 |
新世代の NVLink
 |
NVIDIA V100 の NVIDIA NVLink は前世代比で 2 倍のスループットを提供します。8 基までの NVIDIA V100 を最大 300GB/s で接続することで、単一サーバー上での最高性能を発揮できます。 |
最大効率モード
|
新たな「最大効率モード」によりデータセンターの電源容量はそのままに、ラックあたり計算性能を最大 40% 向上させられます。このモードの NVIDIA V100 は最大性能の 80% を、最大消費電力の半分で実現します。 |
 |
HBM2
 |
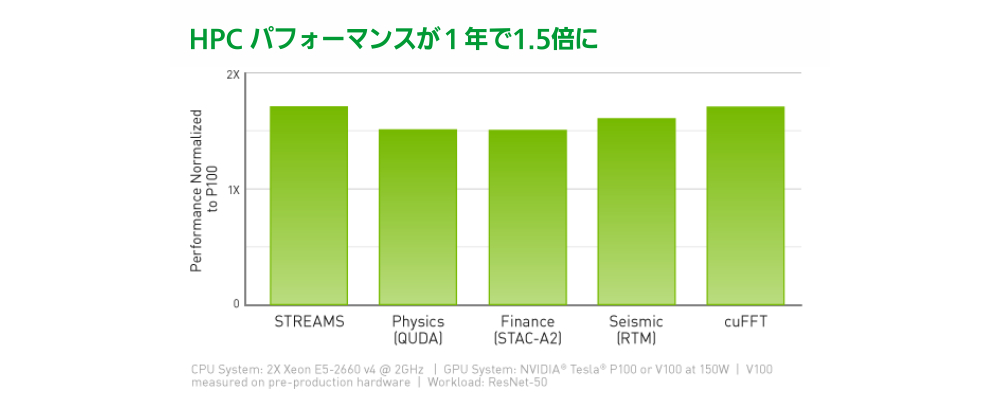
900GB/s に向上した帯域幅と 95% 向上した DRAM 効率により、NVIDIA V100 は STREAM 計測で Pascal GPU 比 1.5 倍のメモリ帯域幅を記録しています。
|
プログラミング効率
|
NVIDIA V100 はプログラムをシンプルにするために設計されました。新しい独立したスレッドスケジューリングにより同期の粒度を細かく設定可能で、小さなジョブを複数同時に処理する効率を高められます。
|
 |
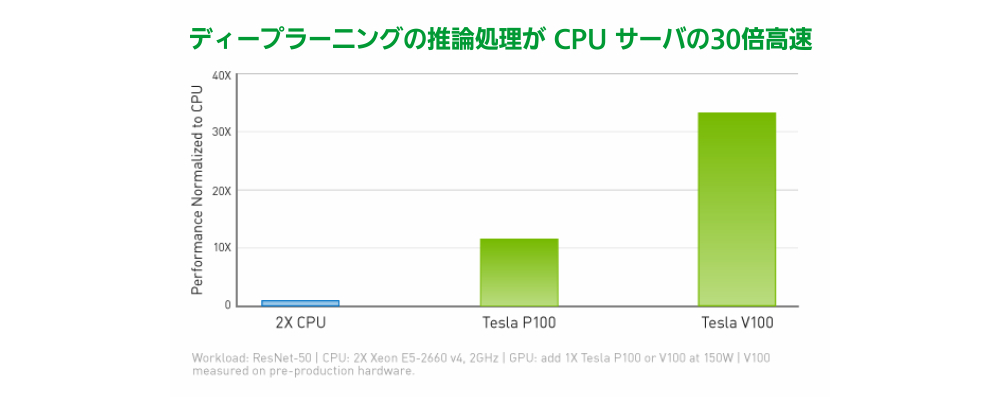
ディープラーニングの推論処理が CPU サーバの30倍高速
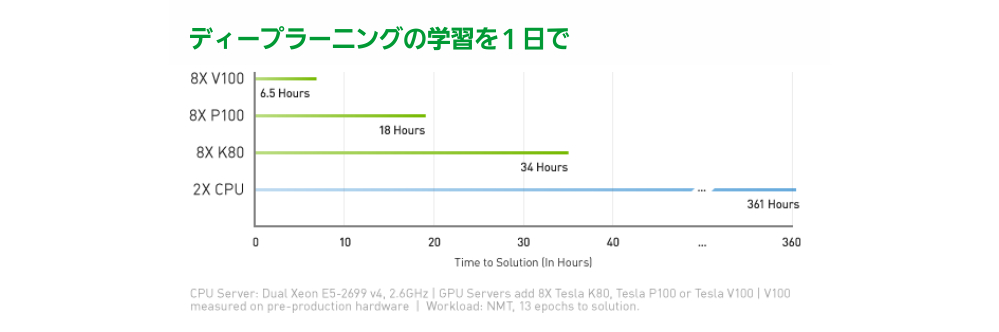
ディープラーニングの学習を1日で
HPC パフォーマンスが1年で1.5倍に
製品仕様
|
NVIDIA V100-PCle |
NVIDIA V100-SXM2 |
|
 |
 |
|
| GPU Architecture | NVIDIA Volta | |
| NVIDIA Tensor Cores | 640 | |
| NVIDIA CUDA Cores | 5,120 | |
| Double-Precision Performance | 7 TFLOPS | 7.8 TFLOPS |
| Single-Precision Performance | 14 TFLOPS | 15.7 TFLOPS |
| Tensor Performance | 112 TFLOPS | 125 TFLOPS |
| GPU Memory | 16 GB HBM2 / 32 GB HBM2 | |
| Memory Bandwidth | 900 GB/sec | |
| ECC | Yes | |
|
Interconnect Bandwidth |
32 GB/sec | 300 GB/sec |
| System Interface | PCIe Gen3 | NVIDIA NVLink |
| Form Factor |
PCIe Full Height/ Length |
SXM2 |
| Max Power Comsumption | 250 W | 300 W |
| Thermal Solution | Passive | |
| Compute APIs | CUDA, DirectCompute, OpenCL, OpenACC | |
弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。

製品案内
- NVIDIA Tensor Core GPU
- NVIDIA H100 NEW
- A800 40GB Active NEW
- NVIDIA A10
- NVIDIA A30
- NVIDIA A100
- NVIDIA V100s
- NVIDIA T4
- NVIDIA V100
- NVIDIA Quadro SERIES
- RTX 4500 Ada NEW
- RTX 4000 Ada NEW
- L40S NEW
- RTX 5000 Ada NEW
- RTX 4000 SFF Ada NEW
- RTX 6000 Ada NEW
- NVIDIA L40
- NVIDIA RTX A5500
- NVIDIA RTX A4500
- NVIDIA A40
- NVIDIA RTX A6000
- NVIDIA RTX A5000
- NVIDIA RTX A4000
- Quadro RTX8000 Passive
- Quadro RTX8000
- Quadro RTX6000
- Quadro GV100
- Quadro GP100
- Quadro P6000
- NVIDIA TITAN SERIES
- NVIDIA TITAN RTX
- NVIDIA TITAN V
- NVIDIA TITAN Xp
- NVIDIA TITAN Xp-SW
- NVIDIA GeForce SERIES
- GeForce RTX3090
- GeForce RTX2080Ti
- GeForce GTX1080Ti
- GeForce GTX1080
- GPUワークステーション
- HPCT WRSE31-4GP
- HPCT WR17as-4GP
- HPCT WR13as-4GP
- HPCT W117gs
- HPCT W116gs
- HPCT W216gs
- HPCT WR16gs
- HPCT WRSX42-4GP NEW
- HPCT WRSX31-4GP
- HPCT WRSX32-4GP
- HPCT WR26gs-Silent
- HPCT WR26gs
- GPUラックマウントサーバ
- HPCT RS2E41-4GP NEW
- HPCT RG2E42-4GPNEW
- HPCT RG2E31-4GP
- HPCT R217gg-4GP
- HPCT RG2E32-8GP
- HPCT R227gg-8GP
- HPCT RS4E42-8GP NEW
- HPCT RS4E32-8GP
- HPCT R427as-8GP
- HPCT R116gs
- HPCT RS1X32-4GP
- HPCT R126gs
- HPCT R126gs-4GP
- HPCT RS2X41-2GP NEW
- HPCT RS2X42-4GP NEW
- HPCT RS2X32-6GP
- HPCT R226gs
- HPCT R426gs-8GP
- HPCT RS4X42-8GP NEW
- HPCT RS4X32-10GP
- HPCT R426gs-10GP
- GPUラックマウントサーバ
- for NVLink - NVIDIA DGX H100 NEW
- NVIDIA DGX A100
- HPCT RS2E32-4GN
- HPCT R227as-4GN
- HPCT RS4X42-4GN NEW
- HPCT RS2X32-4GN
- HPCT R126gs-4GN
- HPCT RS4E32-8GN
- HPCT R427as-8GN
- HPCT RS4X32-8GN
- HPCT R426gs-8GN
- HPCT RX26gs-16GN
- 販売終息製品
- サービス
- セットアップサービス
- DL クラスタ管理
- ベンチマーク情報
- NVIDIA GPU CLOUD
- GPUアプリケーション
- 化学・量子化学
- AMBER
- GROMACS
- NAMD
- 量子化学
- GAMESS-UK
- GAMESS-US
- 物質科学
- VASP
- 数値解析
- MATLABS
- Mathematica
- 数値流体力学
- Ansys Fluent
- 構造力学
- Abaqus
- Ansys Mechanical
- LS-DYNA
- MSC Nastran
- MSC Marc
- 電磁界
- CST Microwave
Studio(MWS) - JMAG
- タンパク質構造解析
- AlphaFold
- RELION
- GPUユーザレポート
- GPU TEST DRIVE CENTER
- GPUテストドライブとは
- HPCT-Trial
- 導入事例
- 会社情報
- サポート
- お取引・お問い合わせ