高度計算機はHPCテックにお任せください。






GPU Solution:NVIDIA GPU
- トップページ
- 製品案内
- GPUラインナップ
- NVIDIA GPU
- NVIDIA H100
NVIDIA H100 Tensor Core GPU


NVIDIA H100 Tensor Core GPUは、最先端の TSMC 4Nプロセスを使用し 800億のトランジスタで構築された世界で最も先進的な Hopperベース の GPUです。PCIe Gen5や HBM3を利用した最初の GPUでもあり 3TB/sのメモリ帯域を実現し、FP64や FP16等に加え FP8で大規模な AIと HPCを加速します。また、メモリは SXM版 PCIe版 どちらも 80GBを搭載し SXM版では HBM3、PCIe版では HBM2eを利用しています。
製品仕様
| NVIDIA H100 SXM |
NVIDIA H100 PCIe |
|
| GPU Architecture | NVIDIA Hopper | NVIDIA Hopper |
| GPU Board Form Factor | SXM5 | PCIe Gen 5 |
| SMs | 132 | 114 |
| TPCs | 66 | 57 |
| FP64 | 34 TFLOPS | 26 TFLOPS |
| FP64 Tensor コア | 67 TFLOPS | 51 TFLOPS |
| FP32 | 67 TFLOPS | 51 TFLOPS |
| TF32 Tensor コア | 989 TFLOPS* | 756 TFLOPS* |
| BFLOAT16 Tensor コア | 1,979 TFLOPS* | 1,513 TFLOPS* |
| FP16 Tensor コア | 1,979 TFLOPS* | 1,513 TFLOPS* |
| FP8 Tensor コア | 3,958 TFLOPS* | 3,026 TFLOPS* |
| INT8 Tensor コア | 3,958 TFLOPS* | 3,026 TFLOPS* |
| メモリインターフェース | 5120-bit HBM3 | 5120-bit HBM2e |
| GPU メモリ | 80 GB | 80 GB |
| GPU メモリ帯域幅 | 3,350 GB/sec | 2000 GB/sec |
| L2 Cache Size | 50 MB | 50 MB |
| Shared Memory Size / SM | Configurable up to 228 KB |
Configurable up to 228 KB |
| Register File Size / SM | 256 KB | 256 KB |
| Register File Size / GPU | 33792 KB | 29184 KB |
| TDP | 700 W | 300-350 W |
| Transistors | 80 billion | 80 billion |
| マルチインスタンス GPU | 最大 7 個の MIG @ 10GB | |
| 相互接続 | NVLink: 900GB/秒 PCIe Gen5: 128GB/秒 | NVLINK: 600GB/秒 PCIe Gen5: 128GB/秒 |
* Shown with sparsity. Specifications 1/2 lower without sparsity.
画期的なイノベーションと強化ポイント
・Transformerネットワークを前世代よりも 6倍高速化する新しい Transformer Engine
・第 2世代の Secure Multi Instance GPU
・処理中に AIモデルと顧客データを保護するコンフィデンシャルコンピューティング
・第 4世代 NVIDIA NVLink
・新しい DPX命令
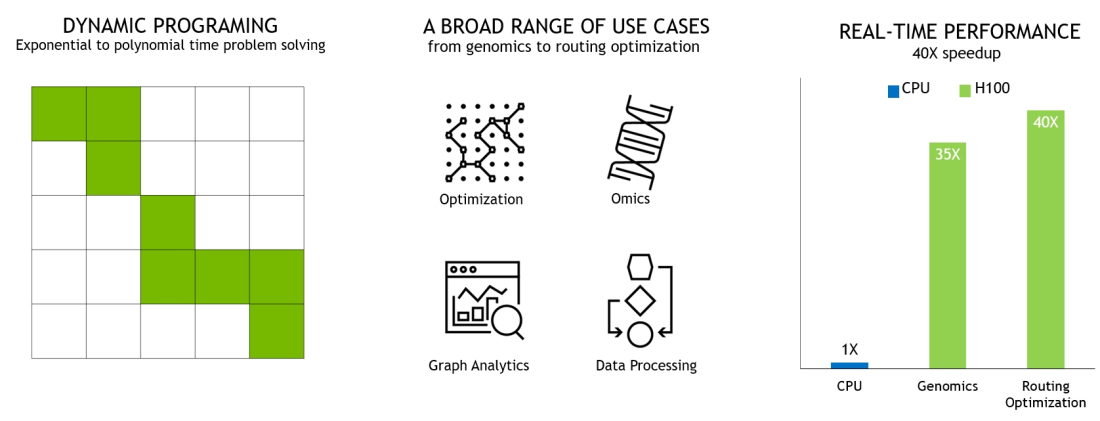
DPX Instructions Accelerate Dynamic Programming
H100は、第 4世代の Tensorコア と新たに搭載された Transformer Engineと FP8の採用によって、Mixture of Experts(MoE)の学習は前世代よりも最大 9倍に、5,300億パラメータからなる Megatron Chatbotの推論は遅延を最小に抑えながら最大 30倍に加速されます。
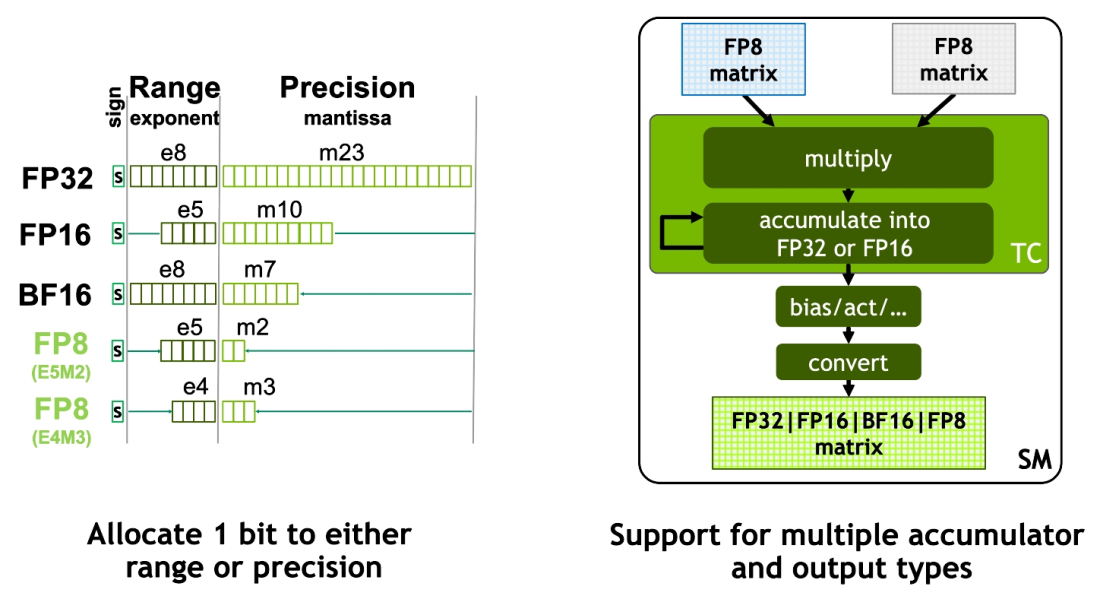
New Hopper FP8 Precisions - 2x throughput and half the footprint of H100 FP16 / BF16
・演算ユニット SMが増加
・L1キャッシュが 256KB、L2キャッシュ が 50MB増加
・第 4世代 Tensorコア は FP8を新しくサポート
・FP32や FP64の FMAが 2倍高速に
・Thread Block Cluster導入(新しい CUDA仕組み)
・TMA(Tensor Memory Accelerator)の導入(非同期データ転送の仕組み)
・第 4世代の NVSwitchに対応(NVLinkだけで最大 256のGPUを接続可)
・世界初の HBM3 GPUメモリアーキテクチャ、帯域幅は前世代の 2倍
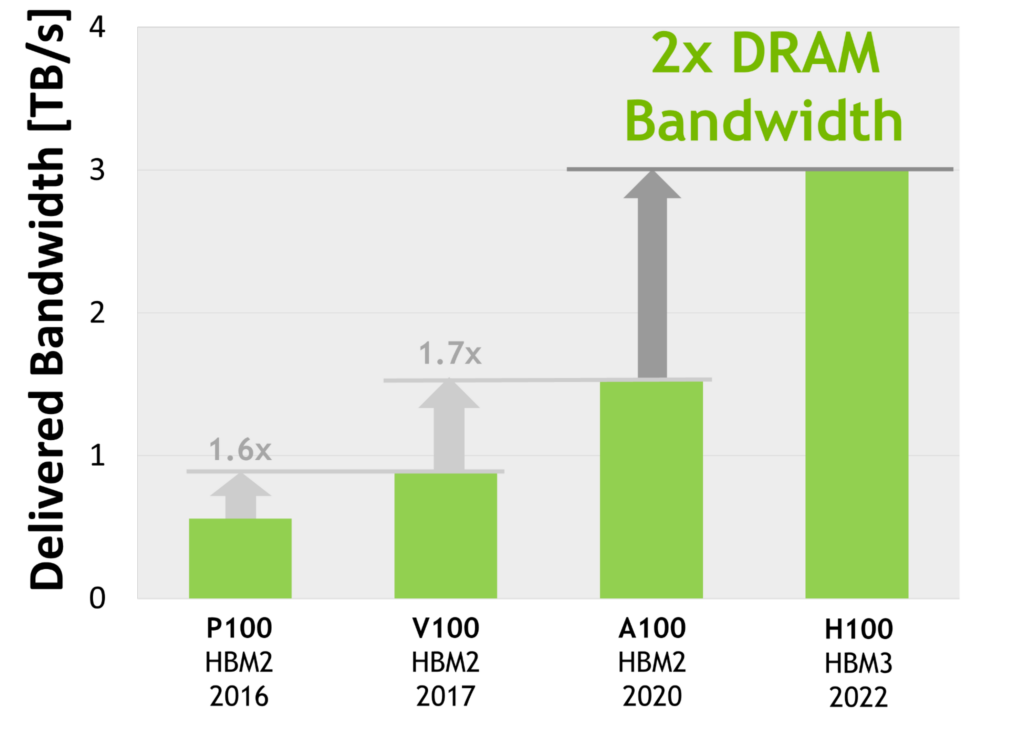
World's First HBM3 GPU Memory Architecture, 2x Delivered Bandwidth

NVIDIA H100-PCIe vs NVIDIA A100-PCIe
| NVIDIA H100 PCIe |
NVIDIA A100 PCIe |
|
| GPU Architecture | NVIDIA Hopper | NVIDIA Ampere |
| Process Node | 4nm | 7nm |
| GPU Board Form Factor | PCIe Gen 5 | PCIe Gen 4 |
| SMs | 114 | 108 |
| TPCs | 57 | 54 |
| FP64 | 24 teraFLOPS | 9.7 TFLOPS |
| FP64 Tensor コア | 48 teraFLOPS | 19.5 TFLOPS |
| FP32 | 48 teraFLOPS | 19.5 TFLOPS |
| TF32 Tensor コア | 800 teraFLOPS* | 400 teraFLOPS | 312 teraFLOPS* | 156 teraFLOPS |
| BFLOAT16 Tensor コア | 1,600 teraFLOPS* | 800 teraFLOPS | 624 teraFLOPS* | 312 teraFLOPS |
| FP16 Tensor コア | 1,600 teraFLOPS* | 800 teraFLOPS | 624 teraFLOPS* | 312 teraFLOPS |
| FP8 Tensor コア | 3,200 teraFLOPS* | 1,600 teraFLOPS | --- |
| INT8 Tensor コア | 3,200 TOPS* | 1,600 TOPS | 1,248 TOPS* | 624 TOPS |
| メモリインターフェース | 5120-bit HBM2e | 5120-bit HBM2e |
| GPU メモリ | 80 GB | 80 GB |
| GPU メモリ帯域幅 | 2,000 GB/sec | 1,935 GB/s |
| TDP | 350 W | 300 W |
| Transistors | 80 billion | 80 billion |
| マルチインスタンス GPU | 最大 7 個の MIG @ 10GB | |
| 相互接続 | NVLINK:600GB/s PCIe Gen5:128GB/s | NVLink:600GB/s PCIe Gen4:64GB/s |
*スパース行列の場合
NVIDIA H100 データシート

NVIDIA H100 Tensor Core GPU Architecture V1.02

弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。

製品案内
- NVIDIA Tensor Core GPU
- NVIDIA H100 NEW
- A800 40GB Active NEW
- NVIDIA A10
- NVIDIA A30
- NVIDIA A100
- NVIDIA V100s
- NVIDIA T4
- NVIDIA V100
- NVIDIA Quadro SERIES
- RTX 4500 Ada NEW
- RTX 4000 Ada NEW
- L40S NEW
- RTX 5000 Ada NEW
- RTX 4000 SFF Ada NEW
- RTX 6000 Ada NEW
- NVIDIA L40
- NVIDIA RTX A5500
- NVIDIA RTX A4500
- NVIDIA A40
- NVIDIA RTX A6000
- NVIDIA RTX A5000
- NVIDIA RTX A4000
- Quadro RTX8000 Passive
- Quadro RTX8000
- Quadro RTX6000
- Quadro GV100
- Quadro GP100
- Quadro P6000
- NVIDIA TITAN SERIES
- NVIDIA TITAN RTX
- NVIDIA TITAN V
- NVIDIA TITAN Xp
- NVIDIA TITAN Xp-SW
- NVIDIA GeForce SERIES
- GeForce RTX3090
- GeForce RTX2080Ti
- GeForce GTX1080Ti
- GeForce GTX1080
- GPUワークステーション
- HPCT WRSE31-4GP
- HPCT WR17as-4GP
- HPCT WR13as-4GP
- HPCT W117gs
- HPCT W116gs
- HPCT W216gs
- HPCT WR16gs
- HPCT WRSX42-4GP NEW
- HPCT WRSX31-4GP
- HPCT WRSX32-4GP
- HPCT WR26gs-Silent
- HPCT WR26gs
- GPUラックマウントサーバ
- HPCT RS2E41-4GP NEW
- HPCT RG2E42-4GPNEW
- HPCT RG2E31-4GP
- HPCT R217gg-4GP
- HPCT RG2E32-8GP
- HPCT R227gg-8GP
- HPCT RS4E42-8GP NEW
- HPCT RS4E32-8GP
- HPCT R427as-8GP
- HPCT R116gs
- HPCT RS1X32-4GP
- HPCT R126gs
- HPCT R126gs-4GP
- HPCT RS2X41-2GP NEW
- HPCT RS2X42-4GP NEW
- HPCT RS2X32-6GP
- HPCT R226gs
- HPCT R426gs-8GP
- HPCT RS4X42-8GP NEW
- HPCT RS4X32-10GP
- HPCT R426gs-10GP
- GPUラックマウントサーバ
- for NVLink - NVIDIA DGX H100 NEW
- NVIDIA DGX A100
- HPCT RS2E32-4GN
- HPCT R227as-4GN
- HPCT RS4X42-4GN NEW
- HPCT RS2X32-4GN
- HPCT R126gs-4GN
- HPCT RS4E32-8GN
- HPCT R427as-8GN
- HPCT RS4X32-8GN
- HPCT R426gs-8GN
- HPCT RX26gs-16GN
- 販売終息製品
- サービス
- セットアップサービス
- DL クラスタ管理
- ベンチマーク情報
- NVIDIA GPU CLOUD
- GPUアプリケーション
- 化学・量子化学
- AMBER
- GROMACS
- NAMD
- 量子化学
- GAMESS-UK
- GAMESS-US
- 物質科学
- VASP
- 数値解析
- MATLABS
- Mathematica
- 数値流体力学
- Ansys Fluent
- 構造力学
- Abaqus
- Ansys Mechanical
- LS-DYNA
- MSC Nastran
- MSC Marc
- 電磁界
- CST Microwave
Studio(MWS) - JMAG
- タンパク質構造解析
- AlphaFold
- RELION
- GPUユーザレポート
- GPU TEST DRIVE CENTER
- GPUテストドライブとは
- HPCT-Trial
- 導入事例
- 会社情報
- サポート
- お取引・お問い合わせ