高度計算機はHPCテックにお任せください。






GPU Solution:NVLink
NVIDIA DGX A100

DGX A100 : 最新 Ampere アーキテクチャ採用 A100 GPU 搭載サーバ

NVIDIA DGX™ A100 は、最新のアーキテクチャ “Ampere” を採用した NVIDIA A100 Tensor コア GPU を8基搭載したサーバです。新 Tensor コアを採用し、「TF32」と呼ばれる、FP32 と FP16 のハイブリッド方式で FP32 演算を行える仕組みを採用しています。前世代の NVIDIA V100 と比較すると約 20 倍の性能を実現しています。(FP32 演算 V100:15.7TFLOPS、A100:312TFLOPS)
また、A100 GPU には 40GB HBM2 と 80GB HBM2e のメモリバージョンがあり、第3世代 NVLink でそれぞれ接続し A100 80GB メモリバージョンでは合計 640GBの大容量メモリと毎秒 2TB/s 超えの世界最速メモリ帯域幅を実現します。プロセッサに AMD EPYC 7742 を 2基搭載しており PCI-Express gen 4.0 をフル活用できます。ストレージには NVMe Gen 4.0 SSD を搭載、外部インターコネクトには Mellanox HDR 200Gbps を搭載しています。これらを備えた NVIDIA DGX A100 の AI 性能は 1ノードで 5PFLOPS に達します。
詳しくは担当までお問い合わせください。 お問い合わせフォーム TEL:03-5643-2681 ![]()
NVIDIA DGX A100 : SYSTEM SPECIFICATIONS
| NVIDIA DGX A100 640GB |
NVIDIA DGX A100 320GB |
||
| GPU | NVIDIA A100 80 GB GPU x8 |
NVIDIA A100 40 GB GPU x8 |
|
| GPU Memory | 640GB total | 320GB total | |
| Performance | 5petaFLOPS AI 10petaOPS INT8 |
||
| NVIDIA NVSwitches | 6 | ||
| System Power Usage | 6.5kW max | ||
| CPU | Dual AMD rome 7742 (128Core Total, 2.25GHz) | ||
| System Memory | 2TB | 1TB | |
| Networking |
8x Single-Port Mellanox ConnectX-6 VPI 10/25/50/100/200 Gb/s Ethernet |
8x Single-Port Mellanox ConnectX-6 VPI 10/25/50/100/200 Gb/s Ethernet |
|
| Storage | OS : 2x 1.92TB M.2 NVMe Drives Internal Storage : 30TB (8x 3.84TB) U.2 NVMe Drives |
OS : 2x 1.92TB M.2 NVMe Drives Internal Storage : 15TB (4x 3.84TB) U.2 NVMe Drives |
|
| Software | Ubuntu Linux OS Also supports: Red Hat Enterprise Linux CentOS |
||
| System Weight | 123Kg | ||
| System Dimensions | H264, W482.3, D897.1 (mm) | ||
| Operating Temperture Range | 5℃ - 35℃ | ||
A100 GPU Memory 40GB から 80GB に倍増
A100 80GB GPU は、高帯域幅メモリが 40GB(HBM2)から 80GB(HBM2e)に倍増し、GPU メモリ帯域幅が A100 40GB GPU を30%上回る世界初の毎秒 2TB 超を実現しています。DGX A100 は第 3世代の NVIDIA NVLink を初めて搭載し、GPU 間の直接帯域幅を毎秒 600GB/s に倍増させています。これは、PCIe Gen4 のほぼ 10倍に相当します。他にも、前世代の 2倍の速度を持つ新しい NVIDIA NVSwitch も搭載しています。このかつてないパワーによって最短でソリューションを実現でき、これまで不可能だったり現実的ではなかったりした課題に取り組めるようになります。
A100 L2 キャッシュ
A100 GPU には、40MB の L2 キャッシュが搭載されており、V100 L2 キャッシュと比べて約 6.7 倍です。L2 キャッシュは2つのパーティションに分割されており、パーティションに直接接続されている GPC 内の SM からのメモリアクセスのデータをローカライズしてキャッシュします。この構造により、A100 は V100 と比較して2.3倍の L2 帯域幅を提供します。ハードウェアキャッシュコヒーレンスは GPU 全体にわたって CUDA プログラミングモデルを維持しており、新しい L2 キャッシュの帯域幅とレイテンシの利点を自動的に活用します。大幅な増加した L2 キャッシュの恩恵は、データセットとモデルの大部分をキャッシュすることで HBM2 メモリよりもはるかに高速な繰り返しアクセスが可能になり、多くの HPC および AI ワークロードのパフォーマンスが向上します。 たとえば、DL 推論ワークロードの場合、ピンポンバッファーを永続的に L2 にキャッシュして、DRAM へのライトバックを回避しながら、より高速なデータアクセスを実現できます。プロデューサ-コンシューマチェーンについては、DLトレーニングで見られるような L2 キャッシュコントロールは、書き込みと読み取りのデータ依存関係全体でキャッシュを最適化できます。 LSTM ネットワークでは、繰り返しの重みを優先的にキャッシュし、L2 で再利用できます。
NVIDIA Ampere アーキテクチャは、計算データ圧縮を追加して、非構造化スパースやその他の圧縮可能なデータパターンを加速します。L2 での圧縮により、DRAM 読み取り/書き込み帯域幅が最大4倍、L2読み取り帯域幅が最大4倍、L2 容量が最大2倍向上します。
マルチインスタンス GPU
マルチインスタンス GPU(MIG)機能により、A100 Tensor コア GPU を CUDA アプリケーション用の最大7つの個別の GPU インスタンスに分割し、複数のユーザーに個別の GPU リソースを提供できます。
MIG は、定義された QoS と VM、コンテナ、プロセスなどの異なるクライアント間の分離を提供し GPU ハードウェアの使用率を向上させます。MIG を使用すると、各インスタンスのプロセッサには、メモリシステム全体を通る個別の分離されたパスがあります。オンチップクロスバーポート、L2 キャッシュバンク、メモリコントローラー、DRAM アドレスバスはすべて、個々のインスタンスに一意に割り当てられます。これにより他のタスクが自分のキャッシュをスラッシングしたり、DRAM インターフェイスを飽和させた場合でも、個々のユーザーのワークロードは同じ L2 キャッシュ割り当てと DRAM 帯域幅で予測可能なスループットとレイテンシで実行できます。これにより、1つのクライアントが他のクライアントの作業やスケジューリングに影響を与えることがなくなり、セキュリティが強化され GPU 使用率が保証されます。
第3世代 NVIDIA NVLink
A100 GPU に実装された第3世代の NVIDIA NVLink インターコネクトと NVIDIA NVSwitch は、マルチ GPU のスケーラビリティ、パフォーマンス、信頼性を大幅に向上させます。GPU とスイッチあたりのリンク数が増えるため、GPU-GPU の通信帯域幅を大幅に向上させエラー検出および回復機能を改善します。第3世代の NVLink は信号ペアあたり 50Gb/s データレートを備えており、これは V100 の 25.78Gb/s のほぼ倍です。単一の A100 NVLink は V100 と同様に各方向に 25GB/s の帯域幅ですが、V100 と比較してリンクあたりの信号ペアの数は半分しか使用しません。このため V100 の 6link、300GB/s に対して 12link、600GB/s の合計帯域幅が得られます。
NVIDIA Magnum IO および Mellanox 相互接続ソリューションのサポート
A100 Tensor コア GPU は、NVIDIA Magnum IO および Mellanox の最新の InfiniBand及びeEthernetと完全に互換性があるマルチノード間の相互接続ソリューションです。Magnum IO API は、コンピューティング、ネットワーキング、ファイルシステム、およびストレージを統合して、マルチ GPU、マルチノードアクセラレーションシステムの I/O パフォーマンスを最大化します。このインターフェイスと CUDA-X ライブラリは AI やデータ分析から視覚化まで幅広いワークロードの I/O を加速します。
SR-IOV を備えた PCIe Gen 4
A100 GPU は、PCI Express Gen 4(PCIe Gen 4)をサポートします。x16 接続で 31.5GB/s となり、PCIe 3.0 の帯域幅である 15.75GB/s の2倍になります。PCIe 4.0 の帯域幅は CPU に接続する A100 GPU や、200Gb/s の InfiniBand など高速ネットワークインターフェイスをサポートする場合はとても有益です。また A100 は SR-IOV もサポートします。これにより複数のプロセスまたは VM の単一の PCIe 接続を共有および仮想化できます。
Performance
トレーニング
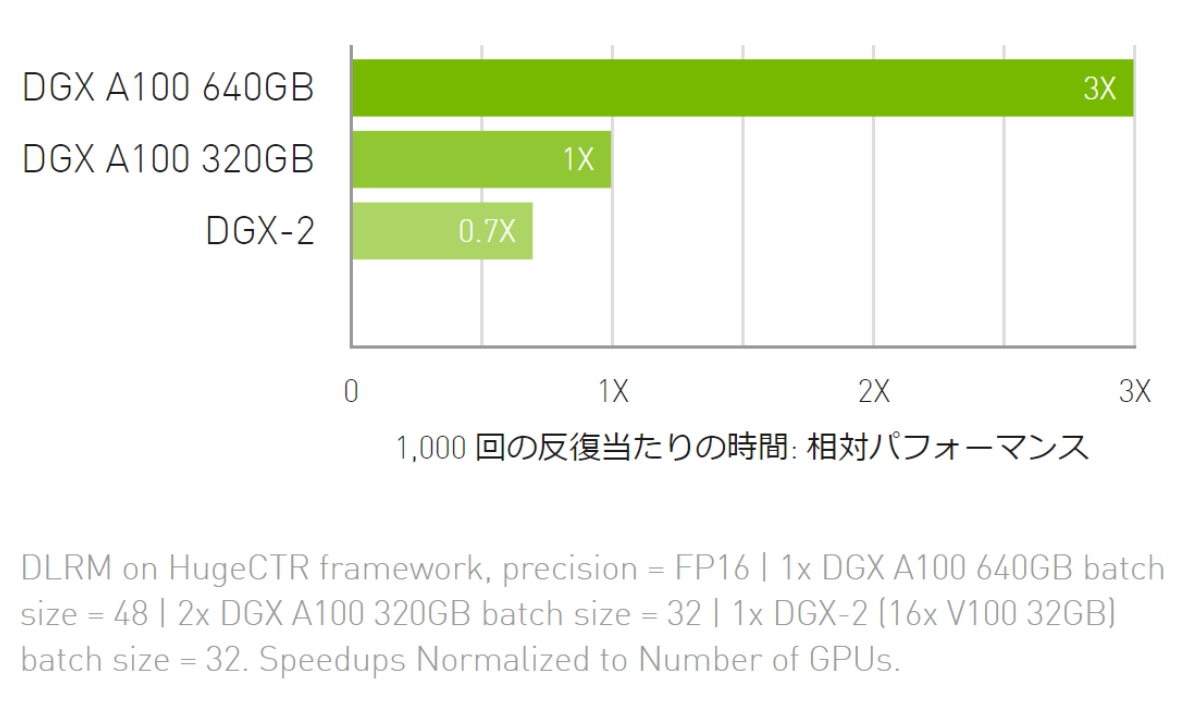
DLRM トレーニング
最大規模のモデルで AI トレーニングのスループットが最大 3倍に向上
推 論
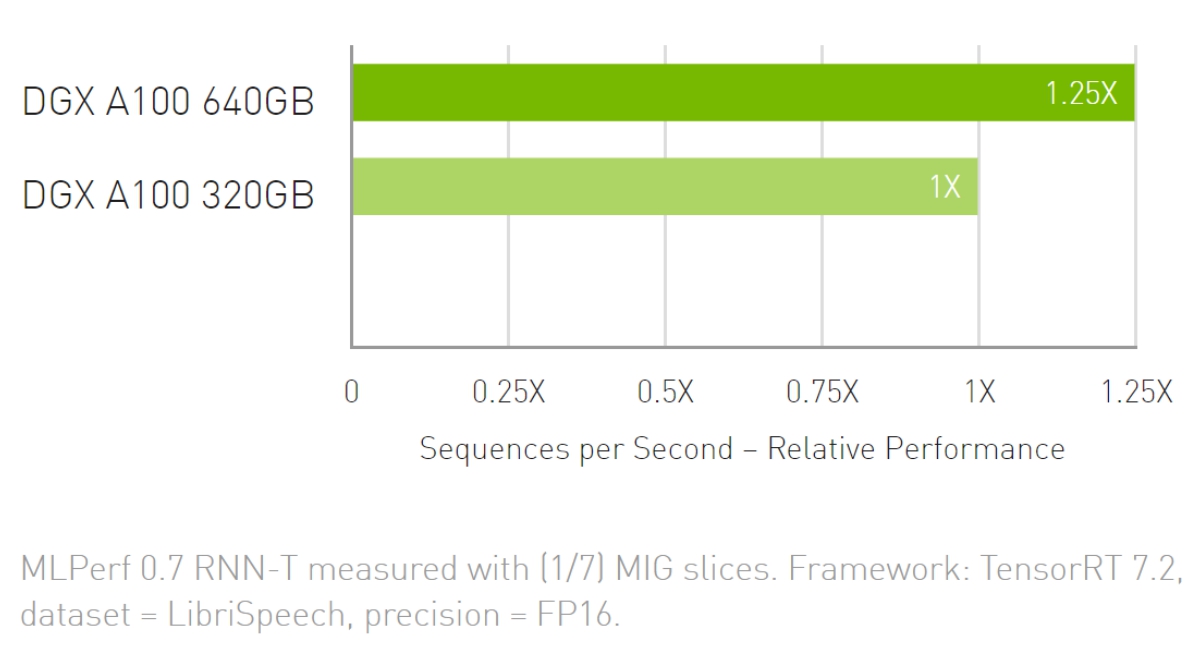
RNN-T 推論:単一のストリーム
AI 推論のスループットが最大 1.25倍に向上
データ分析
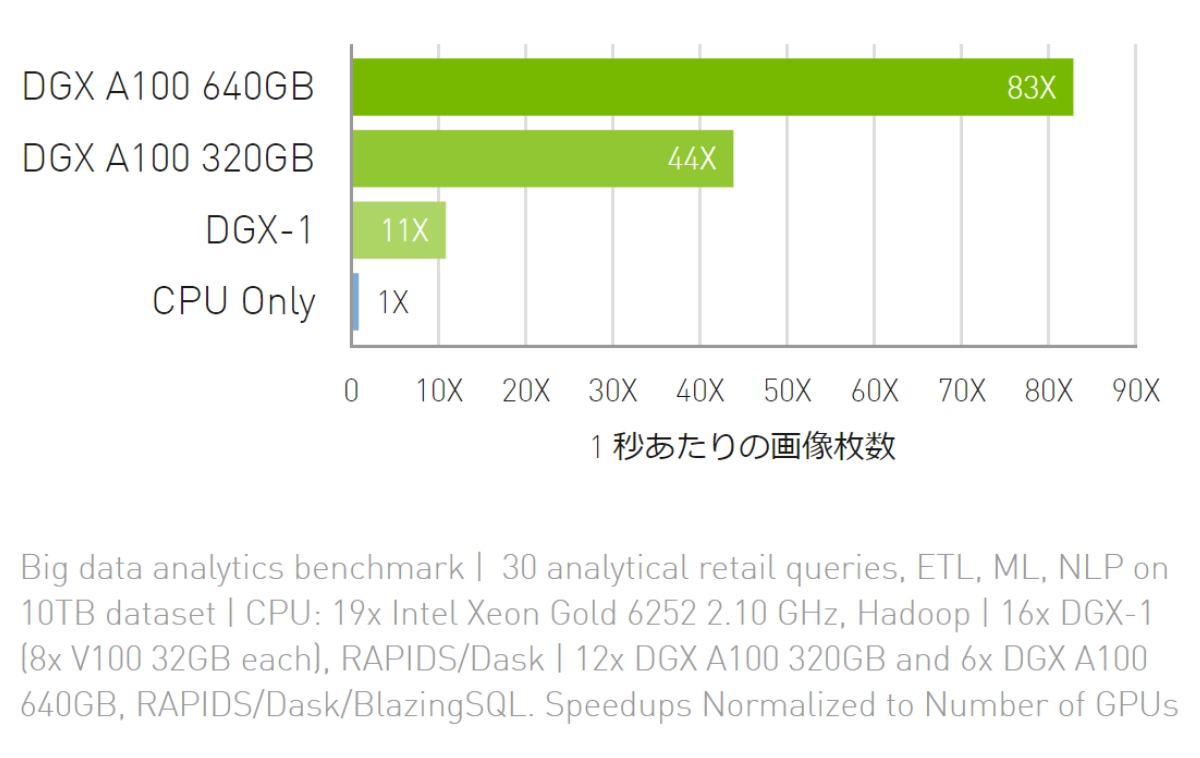
ビッグデータ分析のベンチマーク
CPU より最大 83倍のスループット、DGX A100 320GB より最大 2倍のスループット
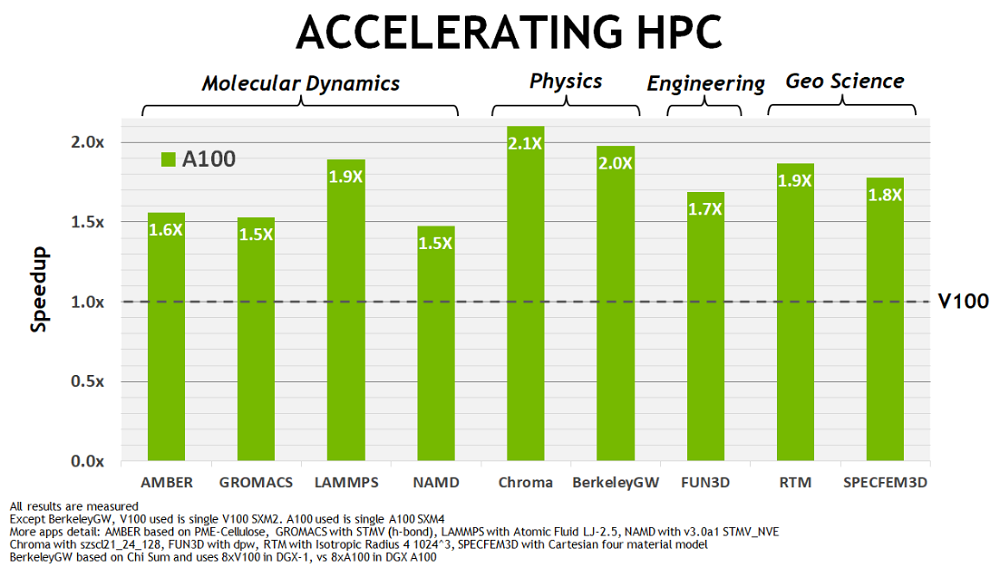
HPC Benchmark
カタログダウンロード

弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。

製品案内
- NVIDIA Tensor Core GPU
- NVIDIA H100 NEW
- A800 40GB Active NEW
- NVIDIA A10
- NVIDIA A30
- NVIDIA A100
- NVIDIA V100s
- NVIDIA T4
- NVIDIA V100
- NVIDIA Quadro SERIES
- RTX 4500 Ada NEW
- RTX 4000 Ada NEW
- L40S NEW
- RTX 5000 Ada NEW
- RTX 4000 SFF Ada NEW
- RTX 6000 Ada NEW
- NVIDIA L40
- NVIDIA RTX A5500
- NVIDIA RTX A4500
- NVIDIA A40
- NVIDIA RTX A6000
- NVIDIA RTX A5000
- NVIDIA RTX A4000
- Quadro RTX8000 Passive
- Quadro RTX8000
- Quadro RTX6000
- Quadro GV100
- Quadro GP100
- Quadro P6000
- NVIDIA TITAN SERIES
- NVIDIA TITAN RTX
- NVIDIA TITAN V
- NVIDIA TITAN Xp
- NVIDIA TITAN Xp-SW
- NVIDIA GeForce SERIES
- GeForce RTX3090
- GeForce RTX2080Ti
- GeForce GTX1080Ti
- GeForce GTX1080
- GPUワークステーション
- HPCT WRSE31-4GP
- HPCT WR17as-4GP
- HPCT WR13as-4GP
- HPCT W117gs
- HPCT W116gs
- HPCT W216gs
- HPCT WR16gs
- HPCT WRSX42-4GP NEW
- HPCT WRSX31-4GP
- HPCT WRSX32-4GP
- HPCT WR26gs-Silent
- HPCT WR26gs
- GPUラックマウントサーバ
- HPCT RS2E41-4GP NEW
- HPCT RG2E42-4GPNEW
- HPCT RG2E31-4GP
- HPCT R217gg-4GP
- HPCT RG2E32-8GP
- HPCT R227gg-8GP
- HPCT RS4E42-8GP NEW
- HPCT RS4E32-8GP
- HPCT R427as-8GP
- HPCT R116gs
- HPCT RS1X32-4GP
- HPCT R126gs
- HPCT R126gs-4GP
- HPCT RS2X41-2GP NEW
- HPCT RS2X42-4GP NEW
- HPCT RS2X32-6GP
- HPCT R226gs
- HPCT R426gs-8GP
- HPCT RS4X42-8GP NEW
- HPCT RS4X32-10GP
- HPCT R426gs-10GP
- GPUラックマウントサーバ
- for NVLink - NVIDIA DGX H100 NEW
- NVIDIA DGX A100
- HPCT RS2E32-4GN
- HPCT R227as-4GN
- HPCT RS4X42-4GN NEW
- HPCT RS2X32-4GN
- HPCT R126gs-4GN
- HPCT RS4E32-8GN
- HPCT R427as-8GN
- HPCT RS4X32-8GN
- HPCT R426gs-8GN
- HPCT RX26gs-16GN
- 販売終息製品
- サービス
- セットアップサービス
- DL クラスタ管理
- ベンチマーク情報
- NVIDIA GPU CLOUD
- GPUアプリケーション
- 化学・量子化学
- AMBER
- GROMACS
- NAMD
- 量子化学
- GAMESS-UK
- GAMESS-US
- 物質科学
- VASP
- 数値解析
- MATLABS
- Mathematica
- 数値流体力学
- Ansys Fluent
- 構造力学
- Abaqus
- Ansys Mechanical
- LS-DYNA
- MSC Nastran
- MSC Marc
- 電磁界
- CST Microwave
Studio(MWS) - JMAG
- タンパク質構造解析
- AlphaFold
- RELION
- GPUユーザレポート
- GPU TEST DRIVE CENTER
- GPUテストドライブとは
- HPCT-Trial
- 導入事例
- 会社情報
- サポート
- お取引・お問い合わせ