高度計算機はHPCテックにお任せください。






GPU Solution:NVIDIA Quadro SERIES
- トップページ
- 製品案内
- GPUラインナップ
- NVIDIA Quadro SERIES
- NVIDIA A40
Ampere アーキテクチャ採用プロフェッショナル用ハイエンドグラフィックスボード

NVIDIA® A40 は NVIDIA Ampere アーキテクチャを採用し、最新のRTコア、Tensorコア、および CUDA コアと 48GB のグラフィックスメモリを搭載したデータセンター向けラックマウントサーバ用 GPU です。レイトレーシングレンダリング、シミュレーション、仮想プロダクションなど最先端の機能を提供します。

― NVIDIA Ampere アーキテクチャ CUDAコア
単精度浮動小数点 (FP32) 操作の処理速度が 2 倍になり、電力効率が改善されたことで、複雑な 3D CAD (コンピューター支援デザイン) や CAE (コンピューター支援エンジニアリング) など、グラフィックスやシミュレーションのワークフローのパフォーマンスが大幅に向上します。
― 第2世代 RTコア
前世代に比べて 2 倍のスループットと、シェーディングやノイズ除去機能と共にレイ トレーシングを並行して実行する能力を備えた第 2 世代 RT コアにより、動画コンテンツの写真のようにリアルなレンダリング、建築デザインの評価、製品デザインの仮想プロトタイプなどのワークロードのための大幅な高速化を実現します。このテクノロジは、より優れた視覚的正確さでより速い結果をもたらすためのレイ トレーシングによるモーション ブラーのレンダリングも高速化します。
― 第3世代 Tensorコア
新しい Tensor Float 32 (TF32) 演算により、前世代に比べて 5 倍のトレーニング スループットを提供するため、コードを変更する必要なく、AI およびデータ サイエンスのモデル トレーニングを高速化します。構造化スパース性に対応するハードウェアにより、推論スループットを 2 倍にします。 Tensor コアはまた、DLSS、AI ノイズ除去、特定のアプリケーション向けの拡張編集などの機能を備えたグラフィックスにも AI をもたらします。
― 第3世代 NVIDIA NVLink
向上した GPU 間の相互接続の帯域幅は、単一のスケーラブルなメモリを提供し、グラフィックスおよび計算処理のワークロードを高速化してより大規模なデータセットへの取り組みを可能にします。
― 48GB GPU メモリ
NVLink を利用して最大 96 GB まで拡張可能な超高速の GDDR6 メモリは、データ サイエンティスト、エンジニア、クリエイティブなプロフェッショナル向けに、データ サイエンスやシミュレーションなどの膨大なデータセットやワークロードを使用する作業に必要な大容量メモリを提供します。
― 仮想化対応
NVIDIA 仮想 GPU (vGPU) ソフトウェアを活用した次世代の改善により、リモート ユーザーがより大規模かつパワフルな仮想ワークステーションのインスタンスを使用できるようになり、高度なデザイン、AI、計算処理におけるより大規模なワークフローが可能になります。
― PCI Express Gen 4
PCI Express Gen 4 対応により、PCIe Gen 3 の 2 倍の帯域幅を提供することで、AI やデータサイエンスなどのデータ集約型タスク向けに CPU メモリからのデータ転送速度が向上します。
― 電力効率
デュアル スロットの省エネ設計を特長とする RTX A6000 は、前世代に比べて 2 倍の電力効率を備え、世界中の OEM ベンダーの幅広いワークステーションに装着できるように開発されています。
GPU でパフォーマンスを加速
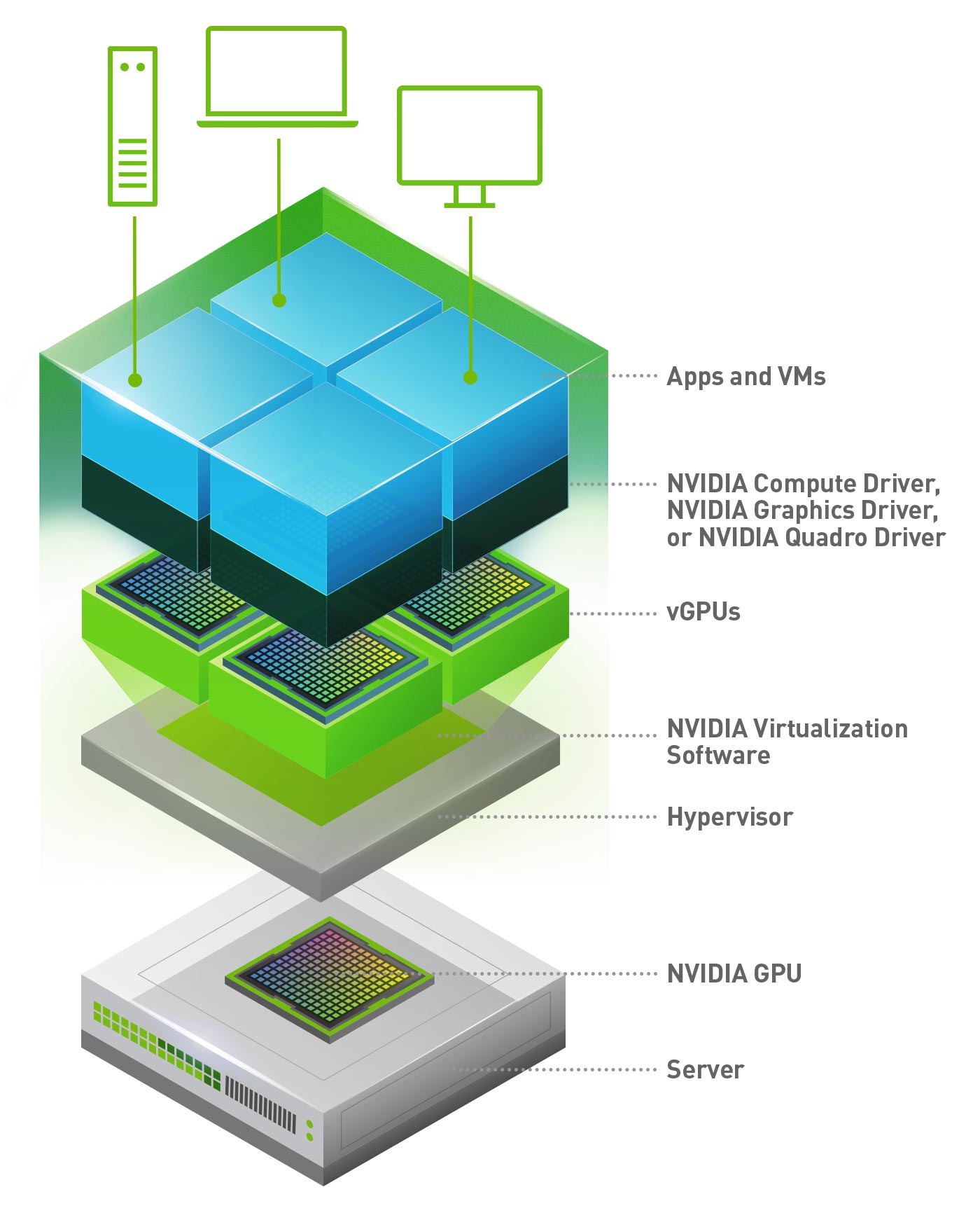
NVIDIA 仮想 GPU(vGPU)テクノロジでは、NVIDIA GPU と NVIDIA 仮想 GPU ソフトウェアのパワーを利用し、AI から仮想デスクトップインフラストラクチャ (VDI) まで、あらゆる仮想ワークロードを高速化します。すべての仮想マシン(VM)に対して GPU 性能を可能にする vGPU テクノロジにより、ユーザーはより効率的かつ生産的に作業を行うことができるようになります。
NVIDIA vGPU の仕組み
・NVIDIA 仮想 GPU を搭載する VDI 環境では、NVIDIA 仮想 GPU ソフトウェアの NVIDIA vGPU Manager をハイパーバイザーのレイヤーにインストール。
・NVIDIA 仮想 GPU ソフトウェアは物理サーバーに搭載されている GPU メモリを分割して仮想 GPU を作成。
複数台の仮想マシン (VM) で物理 GPU コアを共有利用したり、複数の GPU を単一の VM に割り当て利用することも可能。
A PRODUCT FOR EVERY WORKLOAD
NVIDIA 仮想 GPU ソフトウェアは、さまざまな仮想環境での利用ニーズを満たす、4つのエディションをご用意
 |
NVIDIA Virtual Compute Server (vCS: 仮想コンピュート サーバ) AI、ディープラーニング、データ サイエンスのワークロード用。 NVIDIA コンピュート ドライバ。 |
|
NVIDIA Quadro DWS |
 |
 |
NVIDIA GRID Virtual PC |
| NVIDIA GRID Virtual Applications
(GRID vApps: GRID 仮想 アプリケーション) |
 |
プロフェッショナル向け機能
マルチディスプレイ テクノロジ
複数の 8K モニター、ベゼル補正機能を備えた NVIDIA Mosaic、NVIDIA の Warp and Blend SDK のサポートを活用して、大規模な Cave Automatic Virtual Environment (CAVE)、ビデオ ウォール、ロケーションベースのエンターテイメントの構築を推進します。

Quadro Sync
複数の NVIDIA RTX A600 GPUs グラフィックス カードをディスプレイやプロジェクターと同期して、NVIDIA Quadro Sync で大規模なビジュアライゼーションを実現します。

マルチ GPU の拡張性 - NVIDIA NVLink ブリッジ
NVLink をプロフェッショナル アプリケーションに利用すれば、マルチGPU 構成でメモリとパフォーマンスを簡単に拡張できます。さまざまなシステムに組み込めるロー プロファイル設計により NVIDIA NVLink ブリッジは、2 基の RTX A6000 を接続することができます。これにより、最大 112 GB/秒の帯域幅と合計 96 GB の GDDR6 メモリを提供でき、最もメモリ負荷の高いワークロードにも取り組めます。

― NVIDIA A40 データシート

― NVIDIA A40 GPU Accelerator - Product Brief

製品仕様
A40 / A100 / V100 仕様比較
| A40 | A100 | V100s | |
| Architecture | Ampere | Ampere | Volta |
| GPU | GA102 | GA100 | GV100 |
| Tensor Cores | 336 | 432 | 336 |
| RT Cores | 84 | - | - |
| FP32 |
37.4 TFLOPS |
19.5 TFLOPS | 16.4 TFLOPS |
| FP16 Tensor Core | 149.7/299.4* Tensor FLOPS |
312/624* Tensor FLOPS |
130 Tensor FLOPS |
| TF32 Tensor Core | 74.8/149.6* TFLOPS |
156/312* TFLOPS |
- |
| BF16 Tensor Core | 149.7/299.4* Tensor FLOPS |
312/624* Tensor FLOPS |
- |
| INT8 Tensor Core | 299.3/598.6* TOPS |
624/1248* TOPS |
- |
| INT4 Tensor Core | 598.7/1197.4* TOPS |
1248/2496* TOPS |
- |
| VRAM | 48GB GDDR6 | 40GB HBM2 | 32GB HBM2 |
| Memory Boost Clock | 1740 MHz | 1410 MHz | 1597 MHz |
| Memory Band Width | Up to 696 GB/s | Up to 1555GB/s | Up to 1134 GB/s |
| Memory Bus Width | 384 bit | 5120 bit | 4096 bit |
| NVLink | NVLink3 112.5GB/s |
NVLink3 600GB/s |
- |
| Display Connectors | DP 1.4 x3 | - | - |
| TDP | 300W | 250W | 250W |
* 新しいスパース性機能を使用した場合の TFLOPS/TOPS 実効値
弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。

製品案内
- NVIDIA Tensor Core GPU
- NVIDIA H100 NEW
- A800 40GB Active NEW
- NVIDIA A10
- NVIDIA A30
- NVIDIA A100
- NVIDIA V100s
- NVIDIA T4
- NVIDIA V100
- NVIDIA Quadro SERIES
- RTX 4500 Ada NEW
- RTX 4000 Ada NEW
- L40S NEW
- RTX 5000 Ada NEW
- RTX 4000 SFF Ada NEW
- RTX 6000 Ada NEW
- NVIDIA L40
- NVIDIA RTX A5500
- NVIDIA RTX A4500
- NVIDIA A40
- NVIDIA RTX A6000
- NVIDIA RTX A5000
- NVIDIA RTX A4000
- Quadro RTX8000 Passive
- Quadro RTX8000
- Quadro RTX6000
- Quadro GV100
- Quadro GP100
- Quadro P6000
- NVIDIA TITAN SERIES
- NVIDIA TITAN RTX
- NVIDIA TITAN V
- NVIDIA TITAN Xp
- NVIDIA TITAN Xp-SW
- NVIDIA GeForce SERIES
- GeForce RTX3090
- GeForce RTX2080Ti
- GeForce GTX1080Ti
- GeForce GTX1080
- GPUワークステーション
- HPCT WRSE31-4GP
- HPCT WR17as-4GP
- HPCT WR13as-4GP
- HPCT W117gs
- HPCT W116gs
- HPCT W216gs
- HPCT WR16gs
- HPCT WRSX42-4GP NEW
- HPCT WRSX31-4GP
- HPCT WRSX32-4GP
- HPCT WR26gs-Silent
- HPCT WR26gs
- GPUラックマウントサーバ
- HPCT RS2E41-4GP NEW
- HPCT RG2E42-4GPNEW
- HPCT RG2E31-4GP
- HPCT R217gg-4GP
- HPCT RG2E32-8GP
- HPCT R227gg-8GP
- HPCT RS4E42-8GP NEW
- HPCT RS4E32-8GP
- HPCT R427as-8GP
- HPCT R116gs
- HPCT RS1X32-4GP
- HPCT R126gs
- HPCT R126gs-4GP
- HPCT RS2X41-2GP NEW
- HPCT RS2X42-4GP NEW
- HPCT RS2X32-6GP
- HPCT R226gs
- HPCT R426gs-8GP
- HPCT RS4X42-8GP NEW
- HPCT RS4X32-10GP
- HPCT R426gs-10GP
- GPUラックマウントサーバ
- for NVLink - NVIDIA DGX H100 NEW
- NVIDIA DGX A100
- HPCT RS2E32-4GN
- HPCT R227as-4GN
- HPCT RS4X42-4GN NEW
- HPCT RS2X32-4GN
- HPCT R126gs-4GN
- HPCT RS4E32-8GN
- HPCT R427as-8GN
- HPCT RS4X32-8GN
- HPCT R426gs-8GN
- HPCT RX26gs-16GN
- 販売終息製品
- サービス
- セットアップサービス
- DL クラスタ管理
- ベンチマーク情報
- NVIDIA GPU CLOUD
- GPUアプリケーション
- 化学・量子化学
- AMBER
- GROMACS
- NAMD
- 量子化学
- GAMESS-UK
- GAMESS-US
- 物質科学
- VASP
- 数値解析
- MATLABS
- Mathematica
- 数値流体力学
- Ansys Fluent
- 構造力学
- Abaqus
- Ansys Mechanical
- LS-DYNA
- MSC Nastran
- MSC Marc
- 電磁界
- CST Microwave
Studio(MWS) - JMAG
- タンパク質構造解析
- AlphaFold
- RELION
- GPUユーザレポート
- GPU TEST DRIVE CENTER
- GPUテストドライブとは
- HPCT-Trial
- 導入事例
- 会社情報
- サポート
- お取引・お問い合わせ