高度計算機はHPCテックにお任せください。






GPU Solution:NVIDIA GeForce SERIES
- トップページ
- 製品案内
- GPUラインナップ
- NVIDIA GeForce SERIES
- RTX 2080 Ti
Turing アーキテクチャ採用最新フラグシップモデル

― Turing アーキテクチャ TU102 を搭載
GeForce RTX2080Ti は Turing アーキテクチャを採用し、レイトレーシングをアクセラレートする「RT コア」とディープラーニング向けの「Tensor コア」を搭載。さらに次世代超高速 GDDR6 メモリ 11GB によるフラグシップ GPU です。

― 最大の特徴
・リアルタイムレイトレーシングの処理を専門に行う RT コア
従来では膨大な計算と時間がレイトレーシングでは必要でしたが、ポリゴンと光線の衝突判定処理を
専門におこなう RT コアを実装することにより、より現実に近い光と影の描画が可能となりました。
・AI のパフォーマンスを実現する革新的なテクノロジ Tensor コア
Deep Learning を実行する「学習させる」だけではなく、学習させたものを実際に動作させる
「推論」を高速に行うことが可能となりました。リアルタイムレイトレーシング等の処理を行うため
に新しいコアを追加しましたが、特に Tensor コアはディープラーニングの高速化にも焦点をあてた
アーキテクチャになっています。
・製造プロセスが 12nm となり、前世代から比べて微細化
・最大で GeForce GTX 1080 Ti の約 10 倍となる 10G Ray/s のレイトレーシング性能を実現
・グラフィックメモリに「GDDR6」をサポートし、14Gbps の転送速度を実現
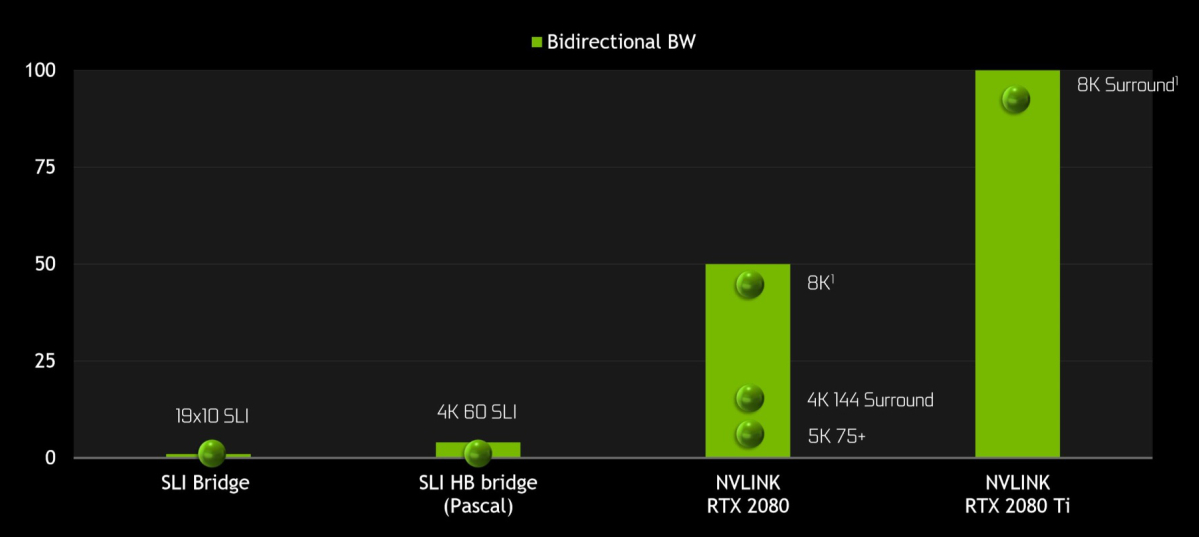
・SLI に変わり、高速 NVLink を採用
従来のテクノロジの 50 倍もの転送帯域幅で 2 つの NVLink SLI 対応グラフィックス カードを接続し、
非常に優れた視覚的忠実度を実現。
・VirtualLink 用の USB コントローラーを内蔵し、背面の出力端子に USB Type-C を搭載
― TU102
TU102 ダイは 6 個の GPC があり、それぞれの GPC は 12 個の SM とラスタライザで構成されており、合計で 72 個の SM が搭載されている。

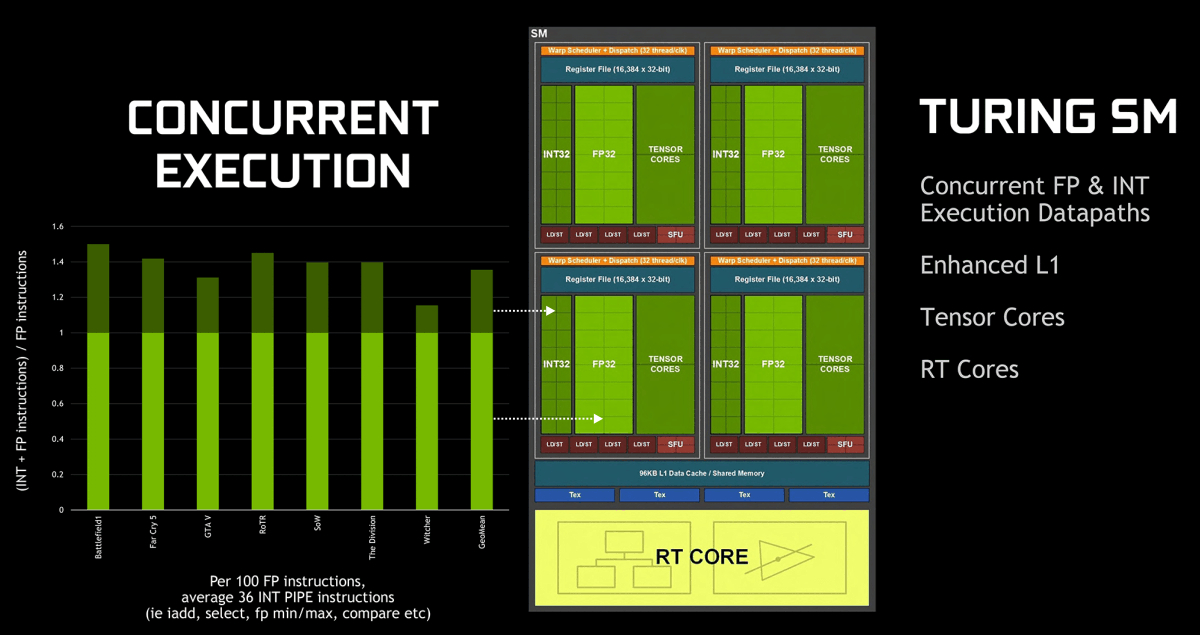
― Turing SM 浮動小数点演算と整数演算を並列に実行可能
― GDDR5X から GDDR6 へ
DDR5X から GDDR6 となり、メモリ転送レートは GDDR5X 11Gbps から、GDDR6 14Gbps へと大幅に高速化されました。
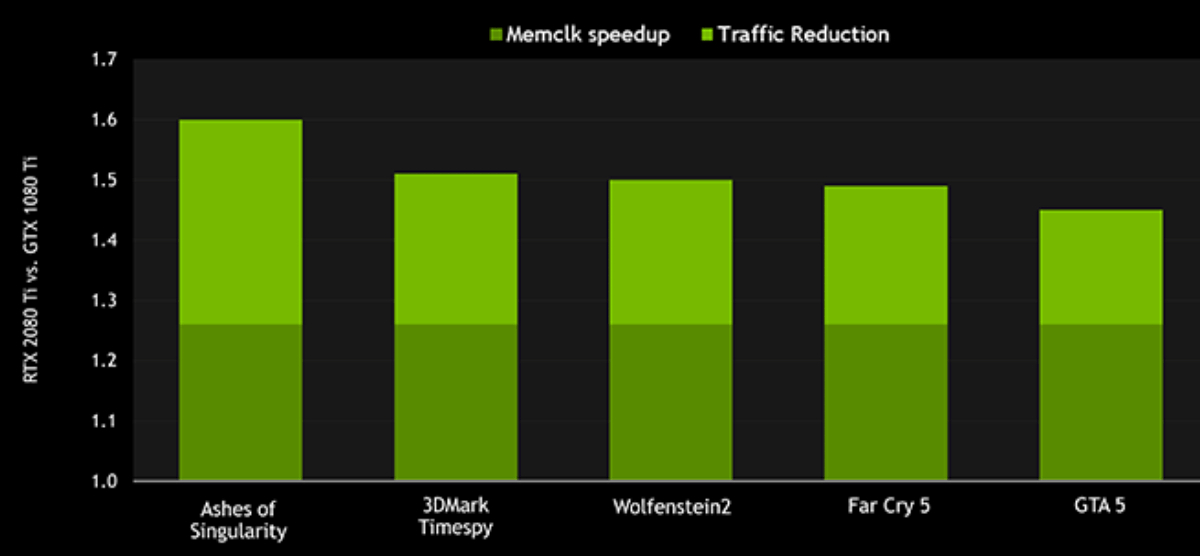
GDDR6 ではメモリの実効率も向上
― 高速インターコネクト NVLink 実装
― HPC テック製 Deep Learning 用ワークステーション&ラックマウントサーバ
HPCテックではワークステーションやラックマウントサーバに搭載し、Caffe や Torch、Tensorflow、NVIDIA DIGITS などをインストールしてお届けしますので届いたその日からディープ・ニューラル・ネットワークの運用や開発を行っていただけます。使い方はそれぞれ違いますので、全てカスタマイズ仕様にてご提案させていただきます。お気軽にご相談ください。
製品仕様
仕様比較
| 製品名 | RTX 2080 Ti | GTX 1080 Ti |
| Architecture | Turing | Pascal |
| GPCs | 6 | 6 |
| TPCs | 34 | 28 |
| SMs | 68 | 28 |
| CUDA Cores / SM | 64 | 128 |
| CUDA Cores / GPU | 4352 | 3548 |
| Tensor Cores / SM | 8 | NA |
| Tensor Cores / GPU | 544 | NA |
| RT Cores | 68 | NA |
| GPU Base Clock | 1350 | 1480 |
| GPU Boost Clock MHz | 1635 (FE) | 1582 |
| Frame Buffer Memory Size and Type | 11GB GDDR6 | 11GB GDDR5X |
| Memory Interface | 352-bit | 352-bit |
| Memory Clock (Data Rate) |
14 Gbps | 11 Gbps |
| ROPs | 88 | 88 |
| Texture Units | 272 | 224 |
| Memory Bandwidth (GB/sec) | 616 GB/sec | 484 GB/sec |
| L2 Cache Size | 5632 KB | 2816 KB |
| Register File Size/SM | 256 KB | 256 KB |
| Register File Size/GPU | 17508 KB | 7168 KB |
| Transistor Count | 18.6 Billion | 12 Billion |
| Die Size | 754 | 471 |
| Manufacturing Process | 12 nm FFN | 16 nm |
| TDP | 260 W | 250 W |
性能比較
| 製品名 | RTX 2080 Ti | GTX 1080 Ti |
| RTX-OPS | 76 Tera-OPS | 11.3 Tera-OPS |
| Rays Cast | 10 Giga Rays/sec | 1.1 Giga Rays/sec |
| Peak FP32 TFLOPS | 14.2 | 11.3 |
| Peak INT32 TIPS | 14.2 | NA |
| Peak FP16 TFLOPS | 28.5 | NA |
| Peak FP16 Tensor TFLOPS with FP32 | 56.9 | NA |
| Peak FP16 Tensor TFLOPS with FP16 | 113.8 | NA |
| Peak INT8 Tensor TOPS | 227.7 | NA |
| Peak INT4 Tensor TOPS | 455.4 | NA |
| Texel Fill-rate | 444.7 Gigatexels/sec | 354.4 Gigatexels/sec |
弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。

製品案内
- NVIDIA Tensor Core GPU
- NVIDIA H100 NEW
- A800 40GB Active NEW
- NVIDIA A10
- NVIDIA A30
- NVIDIA A100
- NVIDIA V100s
- NVIDIA T4
- NVIDIA V100
- NVIDIA Quadro SERIES
- RTX 4500 Ada NEW
- RTX 4000 Ada NEW
- L40S NEW
- RTX 5000 Ada NEW
- RTX 4000 SFF Ada NEW
- RTX 6000 Ada NEW
- NVIDIA L40
- NVIDIA RTX A5500
- NVIDIA RTX A4500
- NVIDIA A40
- NVIDIA RTX A6000
- NVIDIA RTX A5000
- NVIDIA RTX A4000
- Quadro RTX8000 Passive
- Quadro RTX8000
- Quadro RTX6000
- Quadro GV100
- Quadro GP100
- Quadro P6000
- NVIDIA TITAN SERIES
- NVIDIA TITAN RTX
- NVIDIA TITAN V
- NVIDIA TITAN Xp
- NVIDIA TITAN Xp-SW
- NVIDIA GeForce SERIES
- GeForce RTX3090
- GeForce RTX2080Ti
- GeForce GTX1080Ti
- GeForce GTX1080
- GPUワークステーション
- HPCT WRSE31-4GP
- HPCT WR17as-4GP
- HPCT WR13as-4GP
- HPCT W117gs
- HPCT W116gs
- HPCT W216gs
- HPCT WR16gs
- HPCT WRSX42-4GP NEW
- HPCT WRSX31-4GP
- HPCT WRSX32-4GP
- HPCT WR26gs-Silent
- HPCT WR26gs
- GPUラックマウントサーバ
- HPCT RS2E41-4GP NEW
- HPCT RG2E42-4GPNEW
- HPCT RG2E31-4GP
- HPCT R217gg-4GP
- HPCT RG2E32-8GP
- HPCT R227gg-8GP
- HPCT RS4E42-8GP NEW
- HPCT RS4E32-8GP
- HPCT R427as-8GP
- HPCT R116gs
- HPCT RS1X32-4GP
- HPCT R126gs
- HPCT R126gs-4GP
- HPCT RS2X41-2GP NEW
- HPCT RS2X42-4GP NEW
- HPCT RS2X32-6GP
- HPCT R226gs
- HPCT R426gs-8GP
- HPCT RS4X42-8GP NEW
- HPCT RS4X32-10GP
- HPCT R426gs-10GP
- GPUラックマウントサーバ
- for NVLink - NVIDIA DGX H100 NEW
- NVIDIA DGX A100
- HPCT RS2E32-4GN
- HPCT R227as-4GN
- HPCT RS4X42-4GN NEW
- HPCT RS2X32-4GN
- HPCT R126gs-4GN
- HPCT RS4E32-8GN
- HPCT R427as-8GN
- HPCT RS4X32-8GN
- HPCT R426gs-8GN
- HPCT RX26gs-16GN
- 販売終息製品
- サービス
- セットアップサービス
- DL クラスタ管理
- ベンチマーク情報
- NVIDIA GPU CLOUD
- GPUアプリケーション
- 化学・量子化学
- AMBER
- GROMACS
- NAMD
- 量子化学
- GAMESS-UK
- GAMESS-US
- 物質科学
- VASP
- 数値解析
- MATLABS
- Mathematica
- 数値流体力学
- Ansys Fluent
- 構造力学
- Abaqus
- Ansys Mechanical
- LS-DYNA
- MSC Nastran
- MSC Marc
- 電磁界
- CST Microwave
Studio(MWS) - JMAG
- タンパク質構造解析
- AlphaFold
- RELION
- GPUユーザレポート
- GPU TEST DRIVE CENTER
- GPUテストドライブとは
- HPCT-Trial
- 導入事例
- 会社情報
- サポート
- お取引・お問い合わせ