高度計算機はHPCテックにお任せください。






GPU Solution:
NVIDIA DGX-1

NVIDIA TESLA V100 (Volta)搭載 DGX-1

HPCテックでは、最新の Volta アーキテクチャを採用した“TESLA V100”を 8基搭載した “DGX-1 with TESLA V100” の受注を開始します。 TESLA V100 の GPU は TSMC の 12nm プロセス技術を採用して製造され、815mm2 のダイサイズに 210 億トランジスタを集積、CUDA Core 数は 5120 基に達し、NVIDIA 史上最大のプロセッサとなりました。 また、組み合わせるメモリは積層タイプ “HBM2” で、帯域幅は 900GB/s あります。さらに、独自インタフェース “NVLink” は第2世代へと進化し、300GB/s の帯域幅を確保しています。
TESLA V100 (Volta版) アップグレード特典のご案内
これから DGX-1(TESLA P100 Pascal版)を導入されるお客様には、TESLA V100 Volta が発売された際に無償でアップグレードするオプションを付ける事が出来ます。 TESLA V100 Volta 版搭載製品で利用開始時期ずれ込みによる機会利益のロスを抑え、将来的に最新のハードウェア環境のアップデートも保証されています。この機会に是非ともご検討ください。
詳しくは担当までお問い合わせください。 お問い合わせフォーム TEL:03-5643-2681 ![]()
Volta に最適化された NVIDIA ディープラーニングソフトウェア
Caffe、TensorFlow、MXNet といった主要なディープラーニングフレームワークは、GPU によるモデルのトレーニング及び推論の高速化に対応しており、そのために cuDNN、cuBLAS、cuSPARSE、NCCL、TensorRT、DeepStream SDK といった NVIDIA Deep Learning SDK を使っています。
これらのライブラリも Volta アーキテクチャに合わせて更新されました。
・cuDNN7:Pascal 比で Caffe2 での CNN トレーニングが 2.5 倍、
MXNet での RNN トレーニングが 3 倍高速に。
・NCCL2:NCCL はバージョン2で Volta に対応。
・TensorRT 3:P100 比で ResNet50 の推論処理が 3.5 倍高速に。
また、各種ディープラーニングフレームワークに対応した Web インターフェースである
NVIDIA DIGITS も進化しています。
・NVIDIA DIGITS:TensorFlow をサポート。
新たなトレーニング済みモデルをサポート:VGG-16、ResNet50、DetectNet。
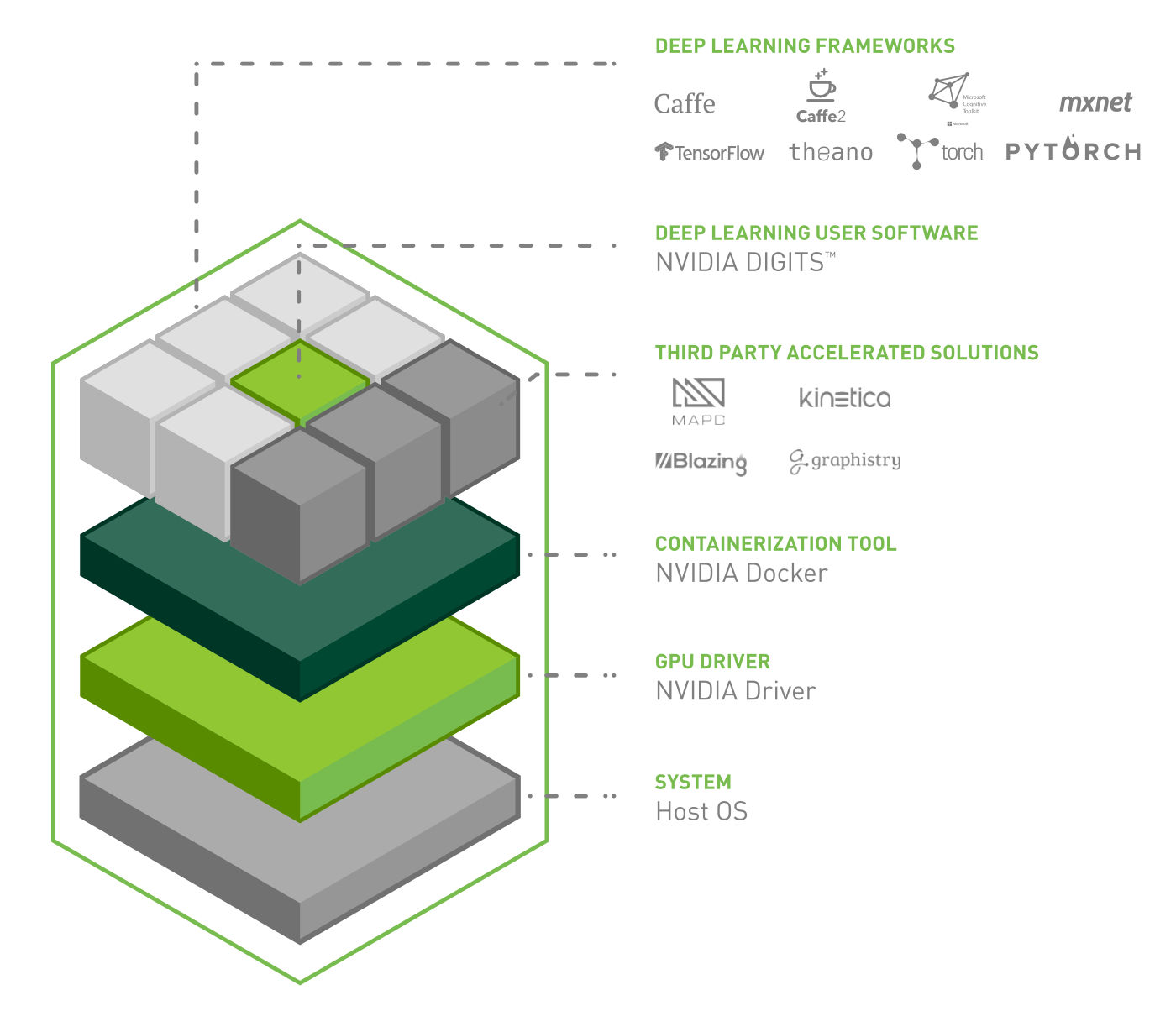
NVIDIA DGX-1 Software Stack
ディープ ニューラル ネットワーク (DNN) の迅速な設計を目的として、主要なディープラーニング フレームワーク、NVIDIA DIGITS™ GPU トレーニングシステム、NVIDIA ディープラーニング SDK (CuDNN、NCCL など)、 NVIDIA Docker、GPU ドライバ、および NVIDIA CUDA が含まれています。
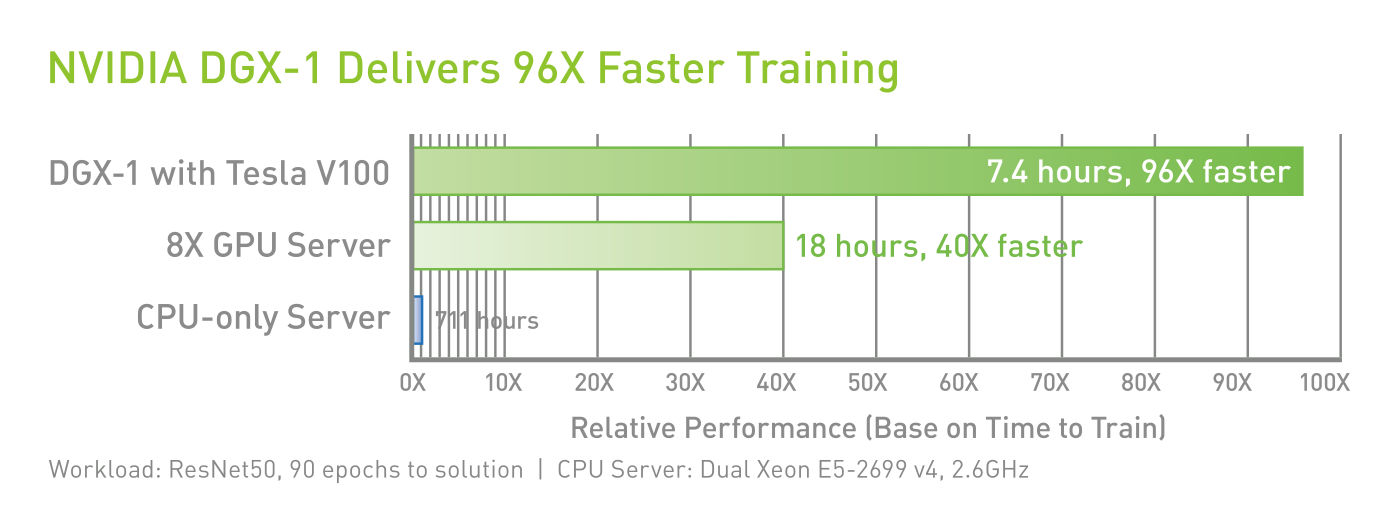
DGX-1 with TESLA V100 Performance

SYSTEM SPECIFICATIONS
| GPU | 8x TESLA V100 | 8x TESLA P100 |
| 演算性能 (GPU FP16) | 960 TFLOPS | 170 TFLOPS |
| GPU メモリ | 256 GB Total System | 128 GB Total System |
| CPU | Intel Xeon E5-2698v4 x2 20 Core, 2.2 GHz |
|
| CUDA コア数 | 40,960 | 28,672 |
| NVIDIA Tensor Cores (on V100 based systems) | 5,120 | N/A |
| 搭載電源容量 | 3,200 W | |
| システムメモリ | DDR4-2133 LRDIMM 512 GB | |
| ストレージ | 4x 1.92 TB SSD RAID0 | |
| ネットワーク | Dual 10 GbE, Up to 4 IB EDR | |
| ソフトウェア | Ubuntu Linux Host OS Software Stack for Details |
|
| 本体 寸法/重量 | 3U, D866 x W444 x H131(mm)/60kg | |
NVIDIA TESLA V100-SMX2

New Tensor Core
TESLA V100 の演算性能は FP64 が 7.5TFLOPS、FP32 が 15TFLOPS、さらに深層学習のアクセラレーションを行うため 4x4 のマトリックス演算を行う“New Tensor Core”を持ち、これにより最大 120TFLOPS の演算性能を実現します。

製品仕様
TESLA V100 / P100 / M40 / K40 仕様比較
| 製品名 | TESLA V100 | TESLA P100 | TESLA M40 | TESLA K40 |
| GPUコア | GV100 (Volta) |
GP100 (Pascal) |
GM200 (Maxwell) |
GK180 (Kepler) |
| 製造プロセス | 12nm FFN | 16nm FinFET | 28nm | 28nm |
| トランジスタ数 | 211億個 | 153億個 | 80億個 | 71億個 |
| SM数 | 80 | 56 | 24 | 15 |
| TPC数 | 40 | 28 | 24 | 15 |
| SMあたりの32FP CUDAコア | 64 | 64 | 128 | 192 |
| 総 32FP CUDA Core 数 | 5120 | 3584 | 3072 | 2880 |
| SM あたりの64FP CUDA Core数 | 32 | 32 | 4 | 64 |
| 総 64FP CUDA Core 数 | 2560 | 1792 | 96 | 960 |
| SMあたりの Tensor Core 数 | 8 | - | - | - |
| 総 Tensor Core 数 | 640 | - | - | - |
| GPU ブーストクロック | 1455MHz | 1480MHz | 1114MHz | 810/875MHz |
| FP32 ピーク演算性能 | 15 TFLOPS | 10.6 TFLOPS | 6.8 TFLOPS | 5.04 TFLOPS |
| FP64 ピーク演算性能 | 7.5 TFLOPS | 5.3 TFLOPS | 2.1 TFLOPS | 1.68 TFLOPS |
| Tensor Core ピーク演算性能 | 120 TFLOPS | - | - | - |
| Texture Units | 320 | 224 | 192 | 240 |
| メモリインタフェース | 4096-bit HBM2 | 4096-bit HBM2 | 384-bit GDDR5 | 384-bit GDDR5 |
| メモリ容量 | 32GB | 16GB | 24GB | 12GB |
| L2キャッシュ | 6MB | 4MB | 3MB | 1.5MB |
| 総レジスタファイル | 20480KB | 14336KB | 6144KB | 3840KB |
| TDP | 300W | 300W | 250W | 235W |
弊社では、科学技術計算や解析などの各種アプリケーションについて動作検証を行い、
すべてのセットアップをおこなっております。
お客様が必要とされる環境にあわせた最適なシステム構成をご提案いたします。

製品案内
- NVIDIA Tensor Core GPU
- NVIDIA H100 NEW
- A800 40GB Active NEW
- NVIDIA A10
- NVIDIA A30
- NVIDIA A100
- NVIDIA V100s
- NVIDIA T4
- NVIDIA V100
- NVIDIA Quadro SERIES
- RTX 4500 Ada NEW
- RTX 4000 Ada NEW
- L40S NEW
- RTX 5000 Ada NEW
- RTX 4000 SFF Ada NEW
- RTX 6000 Ada NEW
- NVIDIA L40
- NVIDIA RTX A5500
- NVIDIA RTX A4500
- NVIDIA A40
- NVIDIA RTX A6000
- NVIDIA RTX A5000
- NVIDIA RTX A4000
- Quadro RTX8000 Passive
- Quadro RTX8000
- Quadro RTX6000
- Quadro GV100
- Quadro GP100
- Quadro P6000
- NVIDIA TITAN SERIES
- NVIDIA TITAN RTX
- NVIDIA TITAN V
- NVIDIA TITAN Xp
- NVIDIA TITAN Xp-SW
- NVIDIA GeForce SERIES
- GeForce RTX3090
- GeForce RTX2080Ti
- GeForce GTX1080Ti
- GeForce GTX1080
- GPUワークステーション
- HPCT WRSE31-4GP
- HPCT WR17as-4GP
- HPCT WR13as-4GP
- HPCT W117gs
- HPCT W116gs
- HPCT W216gs
- HPCT WR16gs
- HPCT WRSX42-4GP NEW
- HPCT WRSX31-4GP
- HPCT WRSX32-4GP
- HPCT WR26gs-Silent
- HPCT WR26gs
- GPUラックマウントサーバ
- HPCT RS2E41-4GP NEW
- HPCT RG2E42-4GPNEW
- HPCT RG2E31-4GP
- HPCT R217gg-4GP
- HPCT RG2E32-8GP
- HPCT R227gg-8GP
- HPCT RS4E42-8GP NEW
- HPCT RS4E32-8GP
- HPCT R427as-8GP
- HPCT R116gs
- HPCT RS1X32-4GP
- HPCT R126gs
- HPCT R126gs-4GP
- HPCT RS2X41-2GP NEW
- HPCT RS2X42-4GP NEW
- HPCT RS2X32-6GP
- HPCT R226gs
- HPCT R426gs-8GP
- HPCT RS4X42-8GP NEW
- HPCT RS4X32-10GP
- HPCT R426gs-10GP
- GPUラックマウントサーバ
- for NVLink - NVIDIA DGX H100 NEW
- NVIDIA DGX A100
- HPCT RS2E32-4GN
- HPCT R227as-4GN
- HPCT RS4X42-4GN NEW
- HPCT RS2X32-4GN
- HPCT R126gs-4GN
- HPCT RS4E32-8GN
- HPCT R427as-8GN
- HPCT RS4X32-8GN
- HPCT R426gs-8GN
- HPCT RX26gs-16GN
- 販売終息製品
- サービス
- セットアップサービス
- DL クラスタ管理
- ベンチマーク情報
- NVIDIA GPU CLOUD
- GPUアプリケーション
- 化学・量子化学
- AMBER
- GROMACS
- NAMD
- 量子化学
- GAMESS-UK
- GAMESS-US
- 物質科学
- VASP
- 数値解析
- MATLABS
- Mathematica
- 数値流体力学
- Ansys Fluent
- 構造力学
- Abaqus
- Ansys Mechanical
- LS-DYNA
- MSC Nastran
- MSC Marc
- 電磁界
- CST Microwave
Studio(MWS) - JMAG
- タンパク質構造解析
- AlphaFold
- RELION
- GPUユーザレポート
- GPU TEST DRIVE CENTER
- GPUテストドライブとは
- HPCT-Trial
- 導入事例
- 会社情報
- サポート
- お取引・お問い合わせ